
Mesh LLM
Pool compute to run powerful open models
65 followers
Pool compute to run powerful open models
65 followers
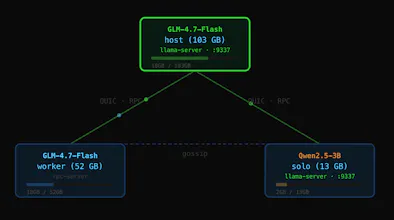
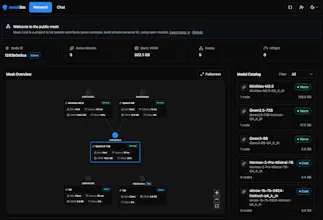
Turn spare capacity into an auto-configured p2p inference cloud. Serve many models, access your private models from anywhere, or share compute with others, let your agents collaborate p2p.


Osaurus
It's SETI at Home but for inference! 🤩
Features.Vote
the auto-configured p2p setup is the clever bit. most self-hosted inference solutions require you to manually manage which node is running what model, handle routing yourself, and accept that you'll be ssh-ing into machines whenever something needs updating. auto-configuring the mesh and exposing a standard openai-compatible endpoint means your existing agent tooling just works without a custom client.
where this gets hard is reliability under real agent workflows. spare capacity is honest framing, but spare capacity is also the most volatile kind. when an agent mid-task makes a follow-up call and the node has dropped or a worker left the mesh, the retry behavior matters a lot. handling partial failures gracefully without surfacing errors to whatever client is consuming the api is a non-trivial coordination problem, especially as the mesh grows beyond a few trusted machines.