
TurboQuant
New LLM compression algorithm by Google
449 followers
New LLM compression algorithm by Google
449 followers
A set of advanced theoretically grounded quantization algorithms that enable massive compression for large language models and vector search engines.




Indie.Deals
Google is on a roll recently, do you think with TurboQuant we can now run powerful LLM models even on a 16GB RAM device?
What is TurboQuant?
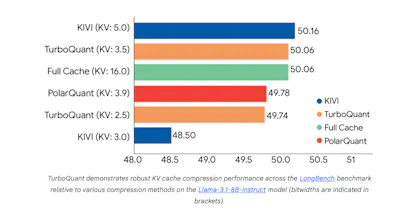
TurboQuant turns one of AI’s biggest hidden bottlenecks, memory, into a solved problem. Probably one of the most important efficiency breakthroughs for large scale AI systems?
It closes the gap between model performance and system limits by massively compressing the vectors that power LLMs and search engines without sacrificing accuracy.
TurboQuant works by rethinking how data is stored and compared. Instead of keeping bulky high precision vectors, it compresses them into ultra compact representations while preserving their meaning and relationships. This allows AI systems to run faster, cheaper, and at much larger scale.
It combines two novel techniques. PolarQuant restructures vector data into a more compressible geometric form, and QJL uses a tiny 1 bit correction layer to eliminate errors. Together, they deliver near lossless compression with almost zero overhead.
Compress once, and everything improves. Memory usage drops, retrieval speeds increase, and long context performance becomes far more efficient.
Key capabilities:
- ultra low bit compression down to about 3 bits
- near zero accuracy loss
- 6x or more reduction in KV cache memory
- faster attention and vector search up to 8x speedups
- no retraining or fine tuning required
In a world where AI is hitting hardware and scaling limits, TurboQuant feels like a fundamental unlock for making models smaller, faster, and more deployable everywhere.
How do you think this will change the game?
@adithya Have you tested TurboQuant on mid-range laptops? Any real-world speed/accuracy numbers for long-context RAG apps?
This is genuinely impressive.
GYST
We got Pied Piper IRL before GTA VI
Vois
This is an absolute game changer! I couldn't wait to run the algorithm on our custom models.