
OrioSearch: Your AI Agent need WebSearch
100% Open-source Tavily alternative. Self-hosted search API
8 followers
100% Open-source Tavily alternative. Self-hosted search API
8 followers
OrioSearch is a self-hosted, Tavily-compatible web search & extraction API. Every AI agent needs web search ! - Drop-in: Matches Tavily's endpoints exactly. - BYO-LLM: Plug in Ollama or OpenAI for AI answers with citations. - Reach: 70+ search engines via SearXNG with DuckDuckGo fallback. - Web + Image search: image results alongside web results via parallel search - Ready: Multi-tier extraction, reranking, SSE streaming & Redis caching.




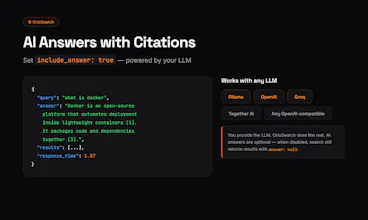





Hey everyone! 👋
Building AI agents and RAG pipelines is incredibly fun, right up until you hit a hard API rate limit or get a surprise bill from your search provider.
I built OrioSearch because I wanted full control over my search stack without rewriting my agent's code. It’s a self-hosted, open-source web search and extraction API that acts as a 100% drop-in replacement for Tavily.
Here’s what it gives you out of the box:
Zero Friction: It's Tavily-compatible. Swap one base URL in your existing code, and everything just works.
Bring Your Own LLM: Works flawlessly with Ollama (free/local), OpenAI, or Groq.
Native AI Answers: Pass include_answer: true to get synthesized responses with citations.
Web + Image search: include_images: true returns image results alongside web results via parallel search
I’d absolutely love your feedback, feature requests, or GitHub PRs. What kind of AI agents are you building, and what would you plug OrioSearch into? Let me know below! 👇