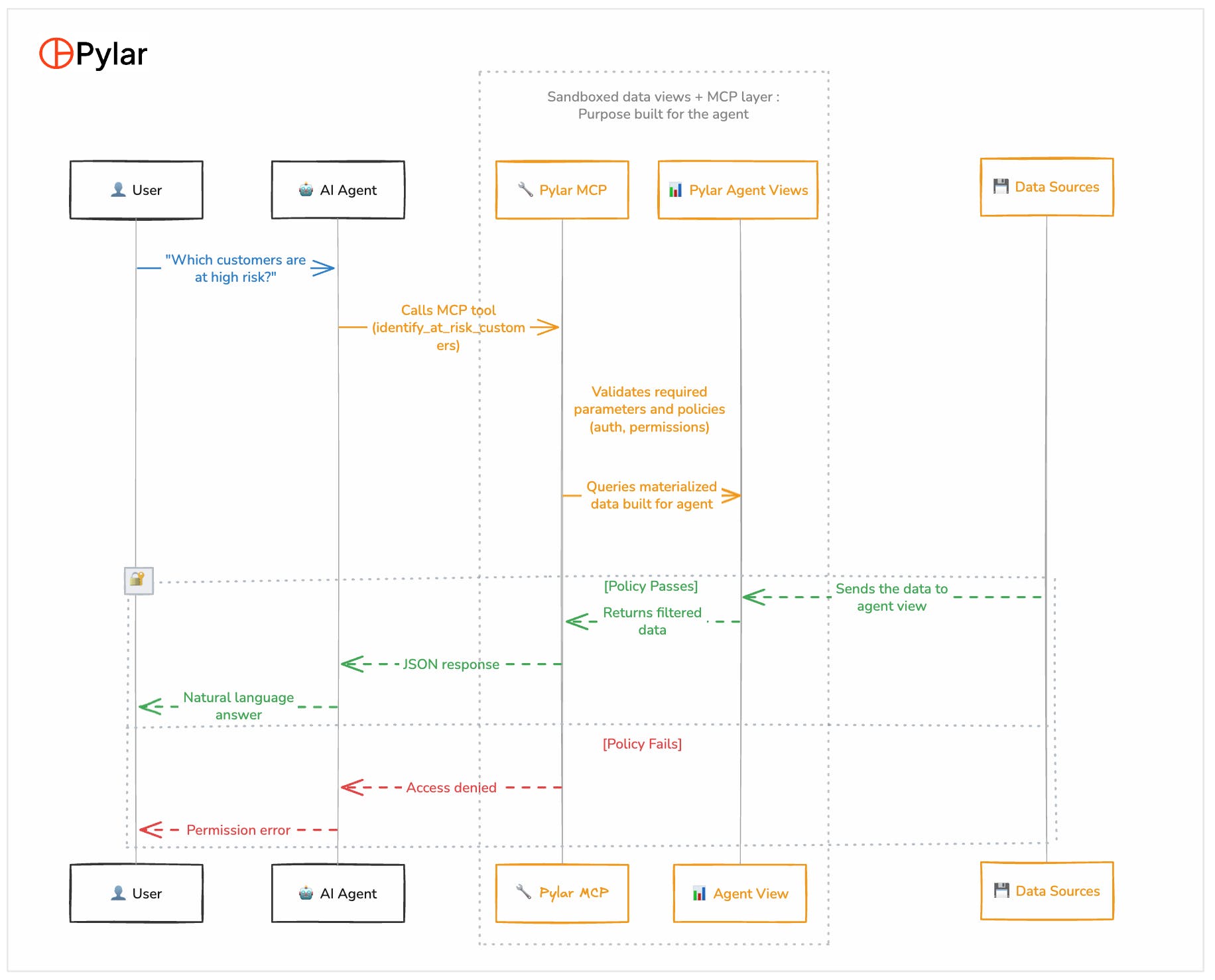
Most AI agents need access to structured data (CRMs, databases, warehouses), but giving them database access is a security nightmare. Having worked with companies on deploying agents in production environments, I'm sharing an architecture overview of what's been most useful- hope this helps!
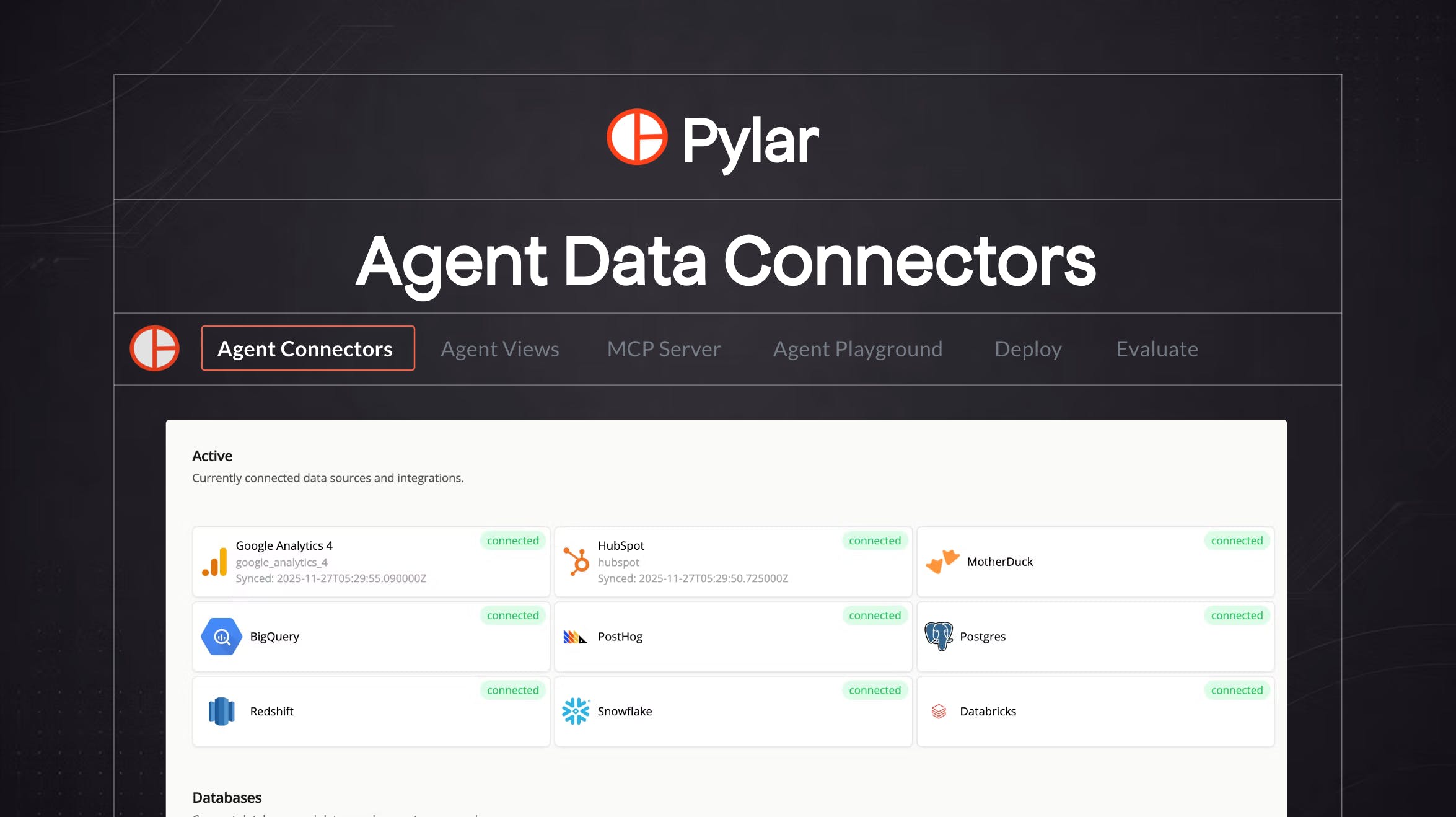
One of the biggest blockers to building agents is getting the data 'agent-ready'. Teams spend months building pipelines, wiring up sources, cleaning data, and centralizing it - before an agent can even ask its first question. Pylar now does this out of the box. We re source-agnostic. Whether your data lives across multiple databases and warehouses (Supabase, Snowflake, MySQL, etc.), you can connect one or many instantly, no re-architecture required. If you don't have a warehouse yet, we ve got you covered. Pylar ships with 100+ built-in integrations across marketing tools, CRMs, support platforms, product databases, and billing systems. Data comes in cleaned, transformed, and centralized, ready for agents to work with. Next up is agent views - once you've connected to your sources, you can write SQL across or within to create precise, sanitized, sandboxed views purpose built for specific agents. Agents don t roam your databases arbitrarily. You deterministically scope exactly what fields they can access, so they do their job well, without hallucinating or giving you different answers for the same/similar questions. Give it a try and let me know what you think!
Today, we re excited to launch Airbook AI - an AI-native workspace to do all your analytics in one place.
Airbook automatically syncs, cleans, and centralizes data from HubSpot, Amplitude, GA4, Zendesk, Stripe, Postgres, Snowflake & more.
Our AI is schema-aware - it understands your question and maps it to the fields that exist in your database, auto-builds queries across sources, and lets you edit everything it generates too- so you're always in control. From there, turn results into dashboards via a prompt or trigger workflows to push data into other growth tools.




 Airbook AI Cursor for Analytics
Airbook AI Cursor for Analytics Airbook's Plug & Play Data Templates50 Actionable Data Templates with Interactive SQL QueriesMay 2023
Airbook's Plug & Play Data Templates50 Actionable Data Templates with Interactive SQL QueriesMay 2023

 Pylar
Pylar