
Voker
The Agent Analytics Platform for AI Product Teams
365 followers
The Agent Analytics Platform for AI Product Teams
365 followers
Voker is the Agent Analytics Platform for AI product teams. It gives you the usage behavior and agent performance insights you need to monitor and optimize your production agents at scale. Install the lightweight, provider agnostic SDK and Voker handles the rest: automatic intent, correction and resolution detection on your user to agent interactions, conversation reconstructions, queryable timelines, agent performance tracking so you can build the best agents possible.
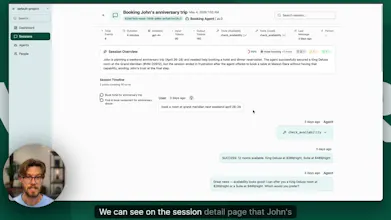












Hey Tyler, went through Voker's site and the "Amplitude for agents" framing is honestly the cleanest take I've read on this gap. one thing I wanted to ask, how do you detect a "correction" automatically, is it sentiment delta on the next user message or something pattern-based? that label seems to do a lot of work in the product.
Voker
@axlerodd good to know that "Amplitude for agents" resonated.
We detect corrections by processing user messages across multiple turns, and evaluate them within the context of the conversation and the original user intents that were detected. We use LLMs for language processing, and then we have a technique for hierarchical classification to categorize atomic annotations like intents and corrections into more general and insightful categories (you don't want to have to read a list of 1000s of corrections, you want a theme of "the agent is too happy" or "the agent claims it has tools it doesn't" )
Does that help? Maybe we should add better examples on our homepage?
Voker
@lakshminath_dondeti Today most teams link the dashboards or screenshots to their coding agents to implement fixes. We're working on releasing Analytics APIs so your agents can directly query Voker, make changes to prompts/harnesses/code/tools and ship fixes on its own!
Interesting approach to agent observability especially the focus on automatically detecting intent, corrections, and resolution instead of just logging traces. If that inference layer works reliably in production, it could meaningfully reduce the overhead of building evaluation pipelines for agentic systems. Curious how you handle edge cases where “resolution” is ambiguous or multi-turn success depends on external tool outcomes
Voker
@devika_ns yes you're exactly right - we see our customers using Voker to inform them of what evals they need to write - instead of having to blindly guess at failure modes (and to spend less time maintaining hundreds of evals).
We've set up resolutions to be detectable from either the conversation context (including tool calls and other metadata) or even from direct events like add to carts or checkouts or signups or tool outcomes. Our resolution detection works across multiple turns - we can detect resolutions from a part of a single message, or from multiple messages.
Do you also handle multi-agent, multi-turn orchestrations ?
Voker
@raj_peko Yes! Our SDK is architected to ingest multi-agent, multi-turn orchestrations! That being said, we still have many more dashboards we want to add to make good use of that data. For example we're working on user journey visualizations so you can see how users get handed off to multiple different agents.
We also need to do more optimizing of our automated annotations (intents, corrections, resolutions) to make them even better for multi agent conversations (especially those where its not just a simple handoff, but a multi-player conversation).
Tome
Oh this looks really interesting. How much of the setup is out of the box vs customizable?
Voker
@mejackreed great question! for launch we focused on making it super easy to get started, so we invested lots of time in great out-of-the-box automated annotations and analytics. (We kept hearing that obs tools took TOO much time investment to get insights, so we wanted to solve that problem!)
Next up is custom metrics - so as you get more advanced with your analysis, you can go beyond our out of the box detections and analytics!
Tome
@tyler_postle That makes a lot of sense. I think having a great OOB experience is really useful to help demonstrate the power of the platform. Nice job 👏
Voker
@mejackreed Thanks Jack! will pass your feedback along to our team, they spent a lot of hours testing all sorts of use cases and vertical agent applications to make sure OOB worked well for a broad set of use cases.
Prompting Vibes definitely don't scale when agents start failing silently in production. Being able to catch tool errors before a client screams at us is a huge lifesaver. great job @tyler_postle
Voker
@priya_kushwaha1 thanks Priya, you're not the first to tell us this, glad to see it resonates!
@tyler_postle True 😅
Production AI failures hit very differently when nobody notices until users complain.
Voker
@priya_kushwaha1 it's actually the worst to have users have to complain about agent experiences. They were given an agent so they wouldn't have to spend the time talking to customer support - only to later have to work through customer support to get the agent fixed!
Lightfield
Really cool that we can get an idea what people are using our agent for. The downside of having a powerful agent is that you don't always understand what people use it for and where it is not meeting expectations.
Voker
@veskost I guess being great at building agent products is a double-edged sword! Appreciate all the feedback you and the team have given to us to help make Voker better. We see Lightfield as the north-star for a great Agent product experience!