
Superchange.ai is an open-source AI agent that collects, classifies, and builds changelogs with updates from tech providers, giving developers one central feed of everything that's new.
New providers added per community requests.
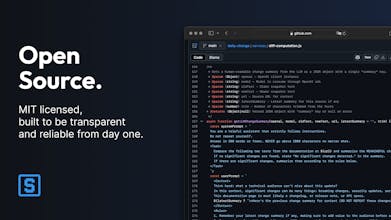
Licensed under Apache-2.0.
Free.






With so so many dependencies, it has been hard keeping track of updates and knowing which ones matter. I've been using it for a few weeks and this AI based approach shows a lot of promise.
Report

Grateful for your support on this journey Alex! Your feedback has been essential in making Superchange.ai better.
Report
Hello hunters! Excited to share a monitoring product I built for myself and my community.
As a product manager, I spent a decade building APIs and development platforms, but I constantly struggled to keep up with others’ changelogs. My projects depend on providers like OpenAI, OSS like Kubernetes, PostgreSQL, and countless others. Yet they move so fast it becomes impossible to stay in sync, plan, build, or maintain.
Panic attack with legacy specs. Death by breaking changes. This pain has accelerated dramatically with the insane AI lifecycles and shipping cadences – things move faster than what one can monitor manually.
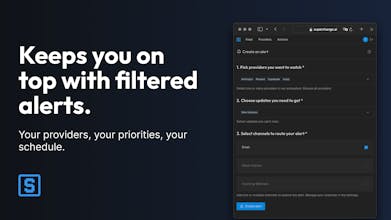
Wait a minute: chaotic, unstructured data are digested by LLMs in no time. What if an AI agent could assist me with scraping, storing, classifying, and alerting my team on the providers we care about? What if I built it myself?
My peers, fellow engineers and product managers used this service, and loved it. So, Superchange.ai was born.
Superchange.ai is open-source, MIT-licensed, built to be reliable and transparent from the start. I value community-driven work and will grow the list of providers with you, listening to your requests.
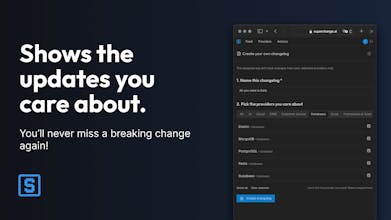
Superchange.ai is free. Anonymous users can access all the data at hand (three months as of writing). Members can customise the log with just what they care about, and set up smart alerts.
No more jumping around changelogs and release notes. We now have ONE source of truth that is easily configurable and publicly sharable to your colleagues for each project.
For example, here’s the changelog tracking the providers used by Superchange: https://superchange.ai/changelog...
What are the use cases? Hear from the beta testers:
Shoutouts - FYI
- Scrapers are happily running daily on free GitHub Actions. The data pipeline has been stable and steady for a quarter, and this is fully open to contributions. I wish to expand to more diverse sources.
- Supabase hosts all the centralised data. Superior dev experience, loving using it.
- The current summariser/classifier is Llama 3.3, which successfully handles large contexts... even massive OpenAPI specs with thousands of line.
This Product Hunt launch aims at accelerating the feedback loop.
How you can support starting today:
Get started (free)
Follow on Github
Contribute with PRs/issues
Share to your fellow devs, product managers!
Super very happy to welcome you to Superchange today, and would appreciate your feedback along the way! 🙏
I love it @thibaultgenaitay
Do you plan to integrate changelogs from Github libraries ? I track changes in libraries with a mix of notifications (Following the repo) and Dependabot PR (when libs are in the stack) but I'd like to "curate" them and incorporate them in the exhaustive view Superchange is bringing.
@thomas__ sounds like a plan! Let me know what you want to track next https://www.superchange.ai/providers/all i'm just getting started ;)
Revel.xyz
this is a must with the crazy churn of the ecosystem we use. congrats @thibaultgenaitay on shipping!
@d_c10 thanks DC, appreciate your support 🙏
Beta Tester here!
As someone responsible for overseeing multiple digital platforms, it's always been a challenge to keep visibility on what's changing across providers. Superchange gives me a clear, consolidated view of breaking changes and new features, allowing me to maintain strategic oversight and better support my team.
Updates are not real-time but come in the next day, which is perfectly acceptable for most operational and coordination needs.
The number of providers currently supported is still limited, but it's growing quickly. There's also a form to request new integrations, and in my experience, the turnaround has been good.
The UI is clean, the changelog summaries are structured and easy to scan, and the whole product feels focused on solving a real problem for complex products.
One feature I'd love to see: the ability to indicate the version we're currently running so that changelogs could be even more tailored, especially for highlighting upcoming deprecations or breaking changes relevant to our deployment.
Looking forward to seeing how this evolves.
@tguillemaud thanks for being part of this fun journey!
Superchange.ai is a gem — finally a clean, open-source way to track AI updates without digging through endless blogs and feeds. Love that it’s MIT-licensed and community-driven too.