
Sense, code intelligence for AI agents
Your AI has your code's text, never its map. Fix that.
13 followers
Your AI has your code's text, never its map. Fix that.
13 followers
Your AI coding agent reads 19 files to answer "who calls this?" because it has your code's text but never its map. Sense indexes your repo once and serves your AI a symbol graph, blast radius, semantic search, and convention detection over MCP. It finishes the same task in half the tool calls and ~32% fewer tokens, with better correctness. One local Go binary. No API key, no cloud, no Python. Works with Claude Code, Cursor, Codex, and OpenCode. Free and open source.


Hey Product Hunters 👋
I'm Luc, and I build with AI coding agents every day. One thing kept bugging me: every time Claude Code or Cursor needs to understand my codebase, it greps around, reads files one at a time, and pieces the structure back together from scratch. It works, but it's slow, it burns tokens, and sometimes it confidently invents a dependency that doesn't exist.
The reason is simple. Your AI has the text of your codebase. It never has the map: who calls what, what breaks if you change this, what patterns your project actually follows.
So I built Sense. It indexes your repo once and gives your AI four things over MCP: a symbol graph (callers, callees, tests, dead code), blast radius ("what breaks if I touch this?"), semantic code search, and convention detection (the patterns your codebase already follows, so AI-written code stops feeling foreign).
The part I care about most: it's not for you, it's for your AI. You install it once and forget it exists. No SaaS account, no API key, no cloud, no Python or Node runtime. One Go binary, a local SQLite index that never leaves your machine, and it works with anything that speaks MCP: Claude Code, Cursor, Codex CLI, OpenCode.
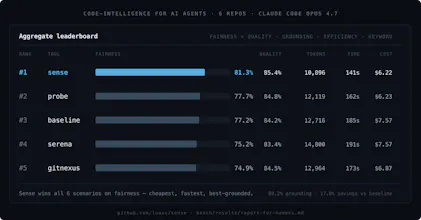
I didn't want to just claim "80% fewer tokens" like everyone does, so I built a reproducible benchmark across 6 real codebases (Discourse, Flask, Next.js, Axum, Gin, Javalin) with published methodology and raw transcripts. On a typical structural task: 19 tool calls drop to ~10, tokens drop ~32%, same correctness. Sense doesn't make the model smarter. It stops the model from wasting effort.
It's free and open source (MIT). Setup is one download and one `sense scan`.
I'd genuinely love your feedback, especially if you point it at a gnarly codebase and your AI does something noticeably better (or doesn't). I'll be here all day answering everything. Thank you for taking a look 🙏