
SemanticGuard
Cuts your LLM API costs by 40-70%. One line of code.
12 followers
Cuts your LLM API costs by 40-70%. One line of code.
12 followers
Most LLM calls in production are repeats. Same questions, same prompts, sometimes worded slightly differently. SemanticGuard caches them. Sits between your app and OpenAI/Anthropic/Google, returns cache hits in <50ms, cuts costs 40-70%. One line of code to install. Shadow Mode shows your savings before you flip caching on. Every hit validated by your own AI so you never serve a wrong answer.


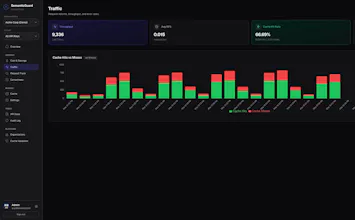

This is such a neat idea, Shadow Mode especially. Really lowers the barrier to just trying it out.
One thing I'm curious about though, how does it handle queries that are semantically close but mean the opposite? Like "which foods are good for high blood pressure" vs "which foods should I avoid for high blood pressure" these would probably sit pretty close in embedding space but serve completely different answers. Does the validator catch that, or is this a known edge case you're still working on?
@amit_kamat1 it's a known case and requires to use the intent as gatekeeper. good catch!