

s1
Matching o1-preview with Only 1000 Examples
6 followers
Matching o1-preview with Only 1000 Examples
6 followers
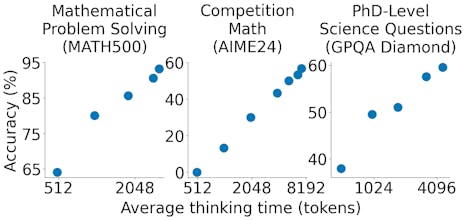
s1 is a simple recipe for test-time scaling of LLMs, achieving strong reasoning performance comparable to o1-preview using only 1,000 examples & budget forcing. Open-source model, data, and code available.




Flowtica Scribe