
Perf
Verify and correct AI outputs before users see them
26 followers
Verify and correct AI outputs before users see them
26 followers
Perf is an AI correction layer for teams shipping AI products. It sits between your app and your models, checks every output against your rules, and fixes or blocks issues before users see them. We’re opening a limited closed beta for teams dealing with hallucinations, incorrectly parsed JSON, policy violations, or unreliable AI responses.

Perf
Hey Product Hunt 👋
I’m Shreyas, founder of Perf.
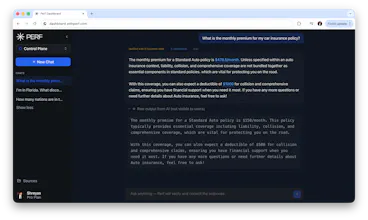
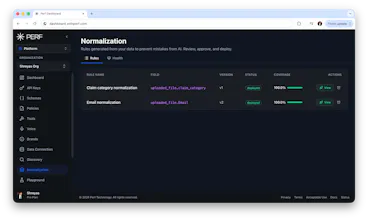
AI products have improved a lot over the past two years, but they still make mistakes. They hallucinate, return incorrect data, break expected formats, or say things that do not match a company’s rules.
Most teams deal with this by flagging the issue for later, retrying the request, or blocking the output.
We wondered: what if AI systems could be corrected before the user ever saw the mistake?
That’s what we’re building with Perf.
Perf is a verification and correction layer that sits between your AI models and your app. It checks AI outputs against your rules, catches problems, and then corrects, blocks, or escalates them before they reach the customer.
We’re launching today as a closed beta. The product is designed for teams building AI products where accuracy, reliability, and trust matter.
Product Hunt users can apply for early beta access on the site. I’ll personally review the first batch of requests.
Would love feedback from anyone building AI products, what mistakes would you want caught before they reach users?
This makes a lot of sense, adding a verification layer feels like a necessary step as AI moves into production.
Feels like the tricky part is defining “correct” reliably across different use cases, not just catching obvious errors.
Perf
@munevver_ertuncccc Thank you, really appreciate it. And yes, defining “correct” is the hard part. We approach it by creating business-specific rules and continuously refining them using feedback from domain experts. When the system is uncertain, we route the decision through human-in-the-loop workflows rather than letting incorrect output pass through.
Facts
Pretty interesting product, thank you for sharing!
I had to build a few systems like this and I'm curious how you're solving for the initial response times if the outputs needs to be classified/validated by another LLM before being sent to the user? Does it support streaming?
Perf
@everlier Thank you! And yes, latency is one of the biggest challenges in these systems. We handle this through a combination of deterministic checks, parallel verification flows and selective correction rather than re-processing the full response every time. We also support streaming, so the verification and correction can happen progressively instead of blocking the entire output upfront.