
GridLLM
Smart inference management across all your compute
8 followers
Smart inference management across all your compute
8 followers
GridLLM is an open-source distributed AI inference platform that turns any computer into a smart inference network. Connect Ollama instances across laptops, servers, and cloud resources for automatic load balancing and scaling.




For the past two years I've worked closely with many different locally hosted models. While I manage several compute clusters, I have always wanted to use my MacBook for additional compute during 24 / 7 agentic tasks. Unfortunately, I never had the tooling that would make that a reality.
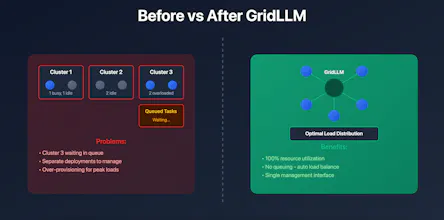
This launch aims to dramatically reduce the complexity of managing a different nodes in a distributed inference network. With GridLLM you can spin up a single server that automatically assigns inference tasks across any of the nodes within your network. This acts using grid-computing principles, and allows you to contribute any unused compute to the overall inference network. For now, it only supports computers that can run the full model locally, but we are working on a way for different clients to take portions of each model, enabling small computers to help run bigger models for the cluster.
GridLLM uses the existing Ollama API specification (https://github.com/ollama/ollama...) and is a plug in replacement. You simply use /ollama endpoint as the base url for all of your calls, and you can plug and play.