Docunerve
PDF extraction API for scanned and digital documents
6 followers
PDF extraction API for scanned and digital documents
6 followers
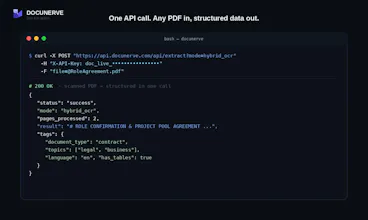
Most parsers break on scanned PDFs. Docunerve triages every page atomatically - digital pages parse instantly, scanned pages route through OCR - and returns clean Markdown, JSON, Text or HTML. Auto tags type, entities and topics on every call. Free to start.