Launched this week

discode.ai
100+ AI models, one interface. ECO friendly.
641 followers
100+ AI models, one interface. ECO friendly.
641 followers
discode is your EU-friendly AI router: one interface for 100+ models, with every prompt auto-routed to the best one for the job. Or fine-tune it yourself along Smarter, Speed and Eco. It shows you which model answered and why, redacts your personal data on-device before anything leaves, checks the hard answers across multiple models, and estimates the CO₂, water and energy footprint of every request. Built in Vienna 🇦🇹. Your AI, your rhythm.




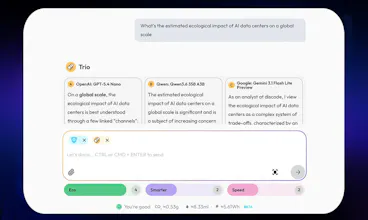


The model-choice reason is the part I’d make very visible.
As a builder, I’d love a tiny “why this route” card that turns each answer into a learning loop: task type detected, constraints it cared about (privacy / latency / quality / eco), and what signal would have pushed it to a stronger model.
That would help users trust the router without needing to understand 100+ model names, and it also gives you cleaner feedback when the route feels wrong.
discode.ai
@grace_lee26 Love this, Grace, thank you. The counterfactual you're describing, "here's the signal that would have bumped this to a stronger model," we don't surface yet, and it's a great call: it turns the card into a learning loop and gives us cleaner feedback when a route feels wrong. Noted.
Is there a way to bring our own API keys for specific models if we already have corporate credits, or is everything managed through a unified discode subscription tier? congrats for shipping @peterbuch 👏
discode.ai
@priya_kushwaha1 thanks Priya, that's a great question. There currently isn't any way to bring corporate credits to discode, but that's certainly something we are looking into.
Happy to chat more, if you have more feedback, thanks again for your support.
@peterbuch Sounds great, thanks for the update 🙌
The eco-slider is interesting! Wondering...When the frugal tier under-serves a hard prompt and I re-ask, that retry probably burns more than just hitting a frontier model once? Does a re-ask count against the eco budget? Showing which model answered and why is the right call regardless!
discode.ai
@artstavenka1 Hi Art, you've put your finger on two of the things we care about most, and the transparency you mentioned, showing which model answered and why, is deliberate for exactly this situation.
On the honest part: yes, a re-ask counts. Every attempt is metered, in cost and in CO₂, water and energy, so on a genuinely hard prompt a couple of tries can outweigh a single direct call. We don't pretend otherwise, and that visibility is the point: you get to see it and decide, rather than us quietly spending more on your behalf.
Where we're headed is smarter about this: escalation that can bump a weak first answer up a tier without a full manual retry, and folding your retries back into routing so the system learns from them. The data for both is already being logged, so it's a matter of wiring it through. Thanks for the nudge, this is exactly the kind of feedback that shapes what we build next.
The Eco routing angle is genuinely interesting but I'd love to know how the difficulty classification works upstream. If the routing decision itself runs on a heavyweight model every time, does that overhead cancel out the savings on simpler queries? Curious if you've benchmarked the router's own footprint.
discode.ai
@vishal_thakor9 Hi Vishal, great question, and exactly the one that would sink the whole idea if we got it wrong.
The router doesn't run on a heavyweight model, and on simple queries it often runs no model at all. It works in two stages: a fast pattern-matching pass reads the domain, language and locale for zero tokens, and a lot of straightforward queries are fully sorted right there. Only when that pass isn't confident does a small classification model step in, and even then it's a tiny call, cached so repeats and near-repeats cost nothing. The routing decision is then frozen for that request, so we never route the same thing twice.
On whether we've measured it: yes. We log each classifier call on its own, so the router's footprint is something we can read directly rather than hand-wave. In practice it's a tiny call set against the savings of keeping a simple request on a lightweight model instead of a frontier one, so the overhead is a rounding error next to that. And the classifier's own cost sits on our side as infrastructure, not on your bill.
One honest nuance: difficulty alone doesn't pick the model. It feeds a tiered score across domain benchmarks, speed, eco and price, weighted by where you've set your sliders, so the classifier informs the decision, it isn't the decision. Happy to go deeper if that's useful.
Mo
@mo_riz Great answer, Mo. The two-stage approach makes a lot of sense — pattern matching first, classifier only as a fallback, is exactly how you'd keep the router from eating its own savings. The caching detail is what I hadn't considered. Does the cache key on semantic similarity or literal request matching? Curious whether two slightly differently worded versions of the same question hit the same cache or get classified fresh.
discode.ai
@mo_riz @vishal_thakor9 thanks for the detailed questions, happy to chat further on e-mail or in on a call if you'd like?
discode.ai
@vishal_thakor9 dear vishal, Thanks — good question! The cache keys on literal matching right now, so two differently worded versions of the same
question get classified independently. Semantic caching is tempting but would introduce exactly the kind of overhead the
router is designed to avoid — embedding calls, similarity thresholds, edge cases. For now, simple and predictable wins. If
the data tells us paraphrased re-asks are a significant share of classifier calls, that's when it earns its complexity.
thanks!
discode.ai
@vishal_thakor9 Vishal, appreciate your question, please let us know if you have any further questions
100+ models behind one interface is a bold scope tbh, curious how you keep the UX from feeling overwhelming when there's that much choice. also the "eco friendly" angle is interesting, what's actually driving that — smarter routing, less wasted compute, or something else.
discode.ai
@martin_mo Martin, agree, it's bold, and it's a lot of models. For us it was important to make sure we have the best model for each task, so we are starting with many. Regarding the ECO we are still in an R&D phase, but what you're mentioning is certainly important: less wasted compute, smarter routing, also using the model that's good enough but not overkill.
@peterbuch good enough but not overkill is such an underrated principle tbh, feels like the industry default is "throw the biggest model at everything" even when a smaller one would do the job fine and way cheaper. curious if you're thinking about exposing that tradeoff to users directly, like letting them pick speed/cost vs max quality per task, or keeping it more automatic under the hood
Cool, it looks lime something I've done on Codex, to setup multi model for every sub agent. discode ai do this thing natively. I think it can save more token and get faster response with simple or complex chat. I'm cursious is discode has a main model to judge and distribute which model should do what?
discode.ai
@sleekzheng Love that you've been building in the space. We do have a main model, but are still optimizing, switching models and doing a lot of testing. What made you use Codex for the task?
Really interesting approach to multi-model access. One thing I've noticed working across different AI models is how differently each one "knows" about specific brands or industries — the variance between ChatGPT vs Gemini vs Claude on the same query can be surprisingly large. Congrats on the launch, curious how you're handling response inconsistency across models!
discode.ai
@magichsin thank you so much for the comment, and the encouraging words. Always happy to chat more.