
bitdrift
Mobile observability & crash reporting, built for apps
80 followers
Mobile observability & crash reporting, built for apps
80 followers
Get real-time visibility into your mobile app. No waiting for release cycles, no extra wiring, no noise. Define what matters remotely, capture rich on-device logs, and surface the most important sessions for quick debugging. Includes free crash reporting.








Hello Product Hunt! 👋 I’m Pete, co-founder and CEO at bitdrift.
For years, we’ve been forced to choose between:
Session replay tools that show what happened but not why
Crash reporters that show stack traces, not context
Expensive observability tools that sample heavily and punish you for logging more
We thought that was ridiculous, so we built a better solution into one lightweight SDK. 😉
With bitdrift, you can:
Monitor real-user performance, sessions, and network behavior
Capture crashes, ANRs, OOMs, and freezes with incredibly rich context
Deploy new monitoring workflows instantly (no app release needed)
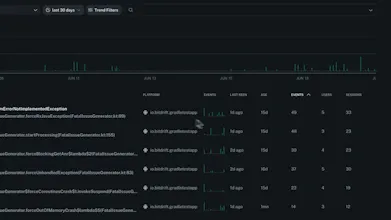
Filter down from millions of user sessions to the one that matters
Store everything you might need locally in a ring-buffer, but only hydrating what matters, so you don’t pay for logs you never look at. (Yes, finally a model that doesn’t punish you for logging everything.)
Today, we’re especially excited to be launching free crash reporting as part of the bitdrift platform. This will allow you to fully replace any existing traditional crash reporting solution, for free! When crashes do happen, the ring buffer provides vastly more information to debug and fix the issue compared to industry standard breadcrumbs.
The bitdrift approach to mobile observability is revolutionary: by coupling a real-time control plane with local on device storage, we're able to send 1000x the data when you need it and none when you don’t. We layer together extremely powerful observability and RUM features that let engineering and product teams debug and fix issues faster than ever.
Our architecture delivers this without cost overruns or performance bloat. You get deep visibility instantly, all without having to wait for mobile release cycles. And now, with crash reporting built in, bitdrift gives you everything you need to provide your customers the best experiences in your app.
Sign up for a free trial and try it out!
Try it now: bitdrift.io/pricing
Learn more: blog.bitdrift.io
Ask us anything, we’ll be hanging out in the comments to answer any questions you might have. Thanks for checking us out!
--pete
Graphite
Congrats on the launch! How does bitdrift change the economics of mobile observability compared to tools that charge per event/for log volume?
@merrill_lutsky Thank you!
Great question on economics. I think volume based pricing generally sets up a pretty antagonistic relationship between developers and the vendor. You're asking mobile engineers to decide at compile time if they should add a log or metric, and given the scale of most mobile deployments vs server side observability, that can get very expensive, very quickly. So, they tend not to. Sure, you can sample aggressively, but now your customers are paying the cost of that lack of visibility. So the way we've architected the system allows us to offer fixed, per device costs, which mean developers just don't have to think about logging, they just log everything.
From a finance perspective, our model is attractive because it's a) very predictable (no overages!) b) aligned with your growth, meaning we grow only when you do and c) sublinear (as you add more, the per unit cost goes down.) As a buyer of these systems for decades, it's rare to find all of these in your infrastructure spend. Put another way, it'll make CFOs and VPs of Eng happy. ;o)
I think this is general observability industry issue, as well, but that's a longer conversation ;o).
Big day and long time coming! Can’t wait to see all the cool ways the ProductHunt community uses bitdrift 🚀
Bookmarked. Looks like an ideal crash reporting solution. Have been looking for another solution to test as I currently use sentry.
When I saw what bitdrift was doing I had flashbacks to moments when I wondered how it was possible to store so many metrics and generate so many logs, yet still never have enough context when something went wrong. Exciting to see how bitdrift's approach will impact mobile observability, and hopefully observability as a whole!
It would be really fascinating to hear about the conversations that lead to the decision that it would be worth it to build bitdrift instead of trying to piece something together with existing solutions.
We have been using Bitdrift for over a year now and it's a total total game changer. We now have full visibility on our mobile devices and with Alerts and Crash Management we can get to source of the problem very quickly on one platform. Its a joy to be working with a company that truly understands mobile Observability - If you are serious about mobile you need this product! Happy to do a call with anyone thats interested to know how we use Bitdrift.
Pete and Team - Keep up the great work. Love al the new stuff your releasing. @pmorelli
Hey Product Hunt! I'm Jackson, one of the founding engineers here at bitdrift — this is the tool I wish I’d had a dozen times over. I'm excited by how bitdrift gives us visibility into mobile experiences in a way that’s never really been possible before, and I think it’s a glimpse at the future of observability itself. Can’t wait for you all to try it!