
Launched this week

zinroute
Cut LLM costs with smart routing & optimization
3 followers
Cut LLM costs with smart routing & optimization
3 followers
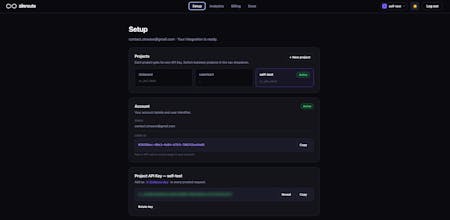
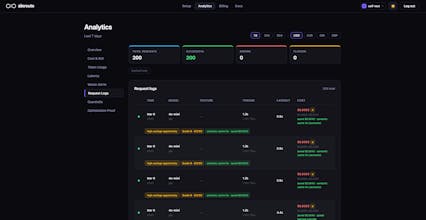
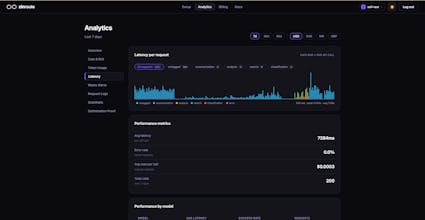
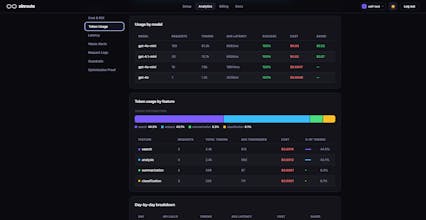
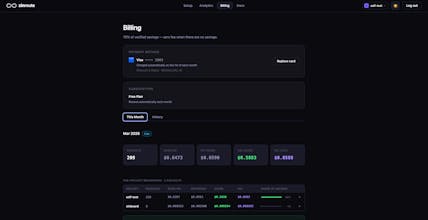
ZinRoute is an LLM optimization layer that reduces AI costs by intelligently routing, caching, and optimizing requests across models and providers. Unlike typical gateways that only forward requests, ZinRoute actively chooses the most cost-efficient model that can deliver the required quality. Features: • Smart cost-aware model routing • Automatic response caching • Cost tracking & analytics • Drop-in OpenAI-compatible API proxy Integrate in minutes and cut LLM costs by up to 70%.



Hi Product Hunt! 👋
I’m Dhanush, the creator of ZinRoute.
While building AI products, I kept running into the same problem — LLM costs explode once you scale. Even simple prompts were going to expensive models when cheaper ones could often do the job just as well.
Most existing tools focus on logging, gateways, or multi-provider access, but I wanted something that actively reduces cost automatically.
So I built ZinRoute — an optimization layer that sits between your app and LLM providers and intelligently decides how each request should be handled.
Instead of just forwarding requests, ZinRoute can:
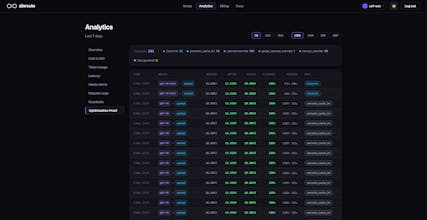
• Route prompts to the most cost-efficient model
• Cache repeated responses automatically
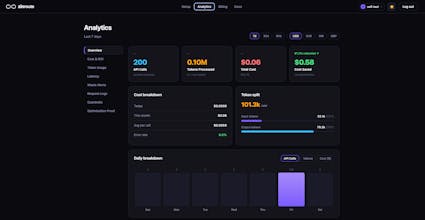
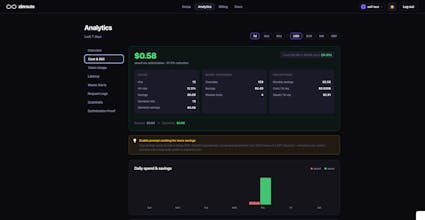
• Track real cost savings across providers
• Reduce latency by avoiding unnecessary heavy models
The goal is simple:
Spend less on LLMs without changing your application logic.
It works as a drop-in OpenAI-compatible API proxy, so integration only takes a few minutes.
I’m also curious how other teams here are handling LLM costs in production.
For teams building AI features:
• What’s your typical monthly OpenAI bill?
• What techniques are you using to control costs?
• Any surprises after moving from testing → real users?
From what we’ve seen, costs can ramp up quickly once usage scales — especially with long prompts, RAG pipelines, and multi-step agents.
Would love to hear how others are approaching this and what’s worked best for you.
Happy to answer questions and hear your feedback 🙌