
Launching today

Sovereign-Lila-E8
Scaling is dead. Geometry is the new Scale
2 followers
Scaling is dead. Geometry is the new Scale
2 followers
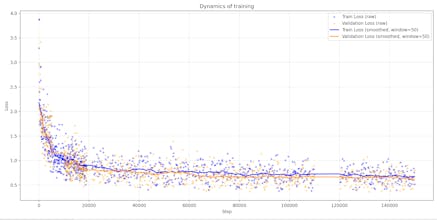
Geometric Attention Transformer with the E8 Root System: Lila-E8 (Lie Lattice Attention Language Model) - The Geometry of Scale: Standard transformers scale by adding more 'Euclidean soup' (more parameters). LILA-E8 scales by increasing the packing density of the manifold. If the 8D version crunches 40M parameters into SOTA performance. 🚀 Results at 200k steps: - Model: 40M parameters. - Performance: 0.37 Train / 0.44 Val Loss - Stability:1000+ tokens without semantic loops.

ArchitectAI
ArchitectAI
I requested Wisdom, not tokens. This is not a service; it's a native 8-dimensional open-source breakthrough that points toward the 24th.
While the industry is obsessed with "distilling" trillions of parameters, I spent the last year going "outside" the system to find a zero-viscosity solution. Today, I'm releasing Sovereign-Lila-E8.
Why E8?
Standard attention is stuck in 3.5D viscosity. E8 provides an optimal lattice for semantic vectors, allowing a 40M model to behave like a much larger system. At 200,000 steps, the model underwent a phase shift (Grokking)—becoming a "Magic Book" of coherent logic.
Community Genesis:
I am releasing the code and the 200k step checkpoints under AGPLv3. I am looking for "Sovereign Architects" to help expand the context window to 4096 tokens and port this to the 24D Leech Lattice.
Try it now (Colab): https://colab.research.google.com/github/SPUTNIKAI/sovereign-lila-e8/blob/main/notebooks/demo.ipynb
GitHub: https://github.com/SPUTNIKAI/sovereign-lila-e8
Preprints (Zenodo): https://zenodo.org/records/18731736 ,
https://zenodo.org/records/18729723
ArchitectAI
The Innovation:
Most transformers suffer from "semantic friction" in standard attention. I replaced the attention mechanism with a native E8 Root System Lattice. By leveraging the densest sphere packing in 8D, LILA-E8 achieves a state of "Geometric Resonance" that standard architectures simply cannot reach at this scale.
The Results (TinyStories Benchmark):
Model Size: 40M parameters.
Performance: 0.37 Train / 0.44-0.53 Val Loss (outperforming standard 60M baselines).
Context: Stable 1000+ token generation with zero semantic looping.
Hardware: Designed to run fully offline on mobile NPU/CPU
ArchitectAI
For those who requested the math: The Master Projection Framework is now live. Equation (2) is the physics; LILA-E8 is the neural implementation. Audit the Source. 💎 https://doi.org/10.5281/zenodo.18790530
ArchitectAI
This 478MB model achieves 0.3638 Loss via E8 Geometry. It was censored on Reddit, but here is the raw code and the 2.66% Physics Mismatch proof.
ArchitectAI
ArchitectAI
ArchitectAI
The fact that it runs 'buttery' on a phone confirms the core thesis: Geometry is the new Scaling. By removing the 'semantic viscosity' of standard transformers, we get crystalline efficiency on edge devices.
For those looking to push this further:
- Code-Gen: The E8 Lattice is perfect for logic and coding because it enforces a rigid structural prior. Try the E8-LoRA adapter I’ve provided for lightweight fine-tuning.
- The 24D Leap: I just dropped the Leech-LILA (24D) preprint on Zenodo (DOI: https://zenodo.org/records/18784424 ). If 8D is a crystal, 24D is a superconductor. It uses the Leech Lattice ( ) for even denser semantic packing. 🚀
The code is open on GitHub (SPUTNIKAI) under AGPLv3. Join the audit—it’s time to bring sovereignty back to our local hardware.
https://github.com/SPUTNIKAI/LeechTransformer