RightNow AI
#1 GPU AI Code Editor
4.7•10 reviews•1.6K followers
#1 GPU AI Code Editor
4.7•10 reviews•1.6K followers
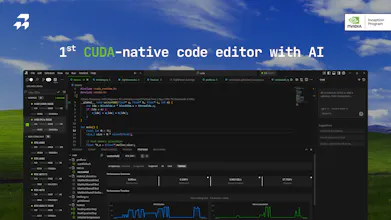
RightNow AI is the #1 GPU AI code editor. It combines GPU profiling, benchmarking, AI optimization, GPU virtualization, and a full GPU emulator in one environment to help developers analyze and optimize CUDA code faster