
MiMo
Xiaomi's Open Source Model, Born for Reasoning
462 followers
Xiaomi's Open Source Model, Born for Reasoning
462 followers
Open-source (Apache 2.0) LLM series 'born for reasoning.' Pre-trained & RL-tuned models (like the 7B) match o1-mini on math/code. Base/SFT/RL models released.
This is the 6th launch from MiMo. View more

MiMo Code
Launched this week
MiMo Code is an open-source terminal AI coding agent built on OpenCode. Optimized for long-horizon tasks, it uses an independent checkpoint subagent to manage unbounded context windows, executes sandbox workflows, and evolves via scheduled maintenance.







Free
Launch Team




Flowtica Scribe
Hi everyone!
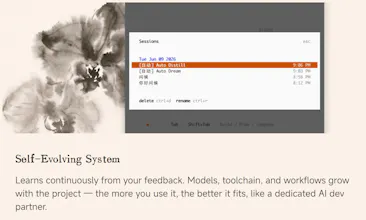
MiMo Code is based on @opencode, but puts more effort into handling long-running sessions.
Instead of letting the main agent manage its own memory, it uses a separate writer subagent that periodically writes structured checkpoints on a schedule.
A key design choice is that these checkpoints are triggered relatively early, well before the context window fills up. This avoids having to do heavy compression under high context pressure.
When the window eventually approaches its limit, the system rebuilds the working context from the accumulated checkpoints and project memory, rather than relying on increasingly unreliable summarization.
It also runs background processes to extract reusable patterns from past work over time.
The separate writer subagent for periodic checkpointing is clever. Triggering early before context pressure builds means you're compressing while you still have bandwidth, not scrambling when the window's nearly full. The naive approach of letting the main agent summarize itself tends to fail exactly when you need it most. When the background process extracts reusable patterns, how do you filter signal from noise across sessions?
The early checkpoint idea makes sense: summarize while the context is still healthy, not when the window is already under pressure.
The hard part I’d worry about is negative memory. If a checkpoint captures a wrong assumption during a long refactor, how does MiMo Code prevent that from being promoted into durable project memory? Do you keep task-local checkpoints separate from reusable MEMORY.md-style knowledge until a later validation pass?
Wrong memory seems more dangerous than no memory on long refactors. If a checkpoint records a bad assumption, can I mark it as wrong before it gets promoted into MEMORY.md, or is cleanup left to the later Dream pass?
Long-term memory in a coding agent is the hard part. When a function gets refactored acroos 10 files, does MiMo-Code update its stored understanding automatically, or do you need to manually invalidate stale context?
The checkpoint subagent idea is the most interesting part to me. Long-horizon coding agents fall apart when context management is implicit. How are you deciding what gets written into long-term memory versus kept as task-local state?
the memory architecture is the part that matters. every AI tool I've used loses everything the moment you close the session and you start from scratch every time. the checkpoint approach where it saves what it learned before the context fills up instead of scrambling to compress after is a smarter design. curious how this scales when projects get really large