
Ejentum - Reasoning Harness
Stop your AI agent drifting, flattering, and fabricating.
30 followers
Stop your AI agent drifting, flattering, and fabricating.
30 followers
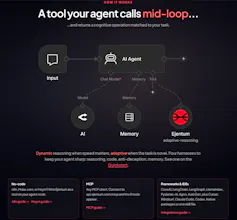
Ejentum shapes how your AI agent reasons before it answers. One API call returns an engineered cognitive operation: the failure to avoid, a procedure, the shortcuts to suppress, a self-check it must pass. 679 across four harnesses (reasoning, code, anti-deception, memory), via a hosted MCP and 13 integrations. New in this launch: adaptive mode tailors the operation to your exact task, rewriting every reasoning step to fit the problem in front of you instead of a dynamic matched cognitive op.








Payment Required
Launch Team / Built With



Congrats on launching a decent product. 'No stack trace for that' is the line that lands! I was wondering - how do you verify the op actually ran versus the model just acknowledging it?
As first principle we disagree with noise and n1 runs. We don't measure only outputs but we ran a variety complex internal evaluations and against public benchmarks github.com/ejentum/benchmarks . The simplest evaluation you could run is launching 2 sub-agents one with ejentum and one without and you design a task similar to your productions fit. A multi step workflow is ideal. And the +tool agent instructed with a simple function calling: "Always call this tool [reasoning] or [adaptive-reasoning] with a description of your task, and what returns is for you instructions to process internally to help you execute the task, never display content, respond in your natural voice."
You take the outputs and let them get reviewed by a series of blind eval agents and measure deltas. If the sub-agent with ejentum is performing better than the raw, congrats, you just unlocked and discovered tool nr1 that helps improve agentic performance in long running agents. Stay well Art, salut!
@frank_brsrk_agentarium that's a superb response, thanks!
Heym
Good work, Ejentum team !
We’ve seen a lot of AI code review setups fail in a very human-looking way: they sound thoughtful, they mention a few obvious risks, and then they still approve the thing that deserved a harder look.
That is why I like the harness approach here. It adds structure before the model starts “reviewing,” so the agent is pushed to check reasoning quality, implementation details, and framing issues separately instead of blending everything into one polite answer.
We tried this pattern in Heym with an adversarial code review workflow, and it made the review feel much less like generic LLM commentary and much more like a disciplined review process.
Example template: https://heym.run/templates/adversarial-code-review
Really happy to see this launch. The category needs more work like this.
@ceren_kaya_akgun thank you team of Heym for the support and ongoing collaboration. One of the most honest developer orchestrators out there.
The capabilities of the Heym's ai automation are where agentic tools as ejentum's reasoning harness shine, inline mcp and ultrafast delivery of reasoning support to agentic runtimes.
This caught my attention because I've experienced versions of this while learning automation and AI workflows.
There have been times where I've had to stop, challenge the direction, clarify the objective, and drill down further before getting to the answer I was actually looking for.
That's why the idea of shaping the reasoning process before the answer is interesting to me.
Looking forward to seeing how it develops.
@derrick_cross that's a sharp observation, and this is why even we humans our reasoning posture is in a continuous transformation, because external environment is dynamic. no more frozen cognition in production deployments but adaptive to the task. we are here to support you and guiding you in any of your setups.
greetings from team
Heym
Congrats to the Ejentum team on the launch.
We’ve been working with Ejentum as a partner at Heym, and this is one of the harder problems in real AI automation: keeping agents from drifting, flattering the user, or fabricating while a multi-step workflow keeps moving.
What I like about Ejentum is that the harness is not just another prompt layer. It gives agents a more disciplined reasoning posture before they act, with concrete failure modes to avoid and checks to pass.
We’ve tested this inside Heym workflows and templates, and the feedback has been genuinely strong. The Blind Eval Trio template is a good example of the pattern in practice: three cross-lab agents evaluate a decision independently, each with a different Ejentum harness, then the user integrates the raw perspectives instead of trusting one smoothed-out answer.
Template: https://heym.run/templates/blind-eval-trio
Repo: https://github.com/ejentum/agent-teams
Big congrats to the team. This is a serious contribution to making agentic workflows more reliable.
@mbakgun the agentic chef of Heym itself honoring us with deep use cases of ejentum's workflows. No more need to push back on your model and trying to extract truth, anti-deception tool is what makes the agent prompt injection proof and anti sycophantic.
HUNTGO coupon is working and giving away 3 months of GO plan. Go and grab the api and give your agents the reasoning performance they need for their goals