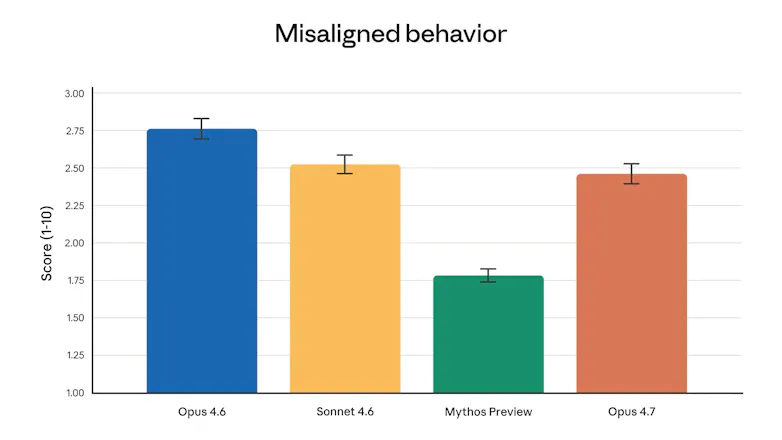
I spent almost a week working with Claude Opus 4.7 and used around 1B tokens. For me, the biggest improvement is not only code quality, but planning quality.
Compared with previous models, Opus 4.7 produces more structured, deeper, and more useful implementation plans. It can work across complex codebases, reason through multi-step changes, and generate code that more often passes linters, integration tests, and review gates on the first run.
What makes it fantastic is that it changes how you work. You are no longer only asking the model to write small functions or boilerplate. You can ask it to plan and execute larger engineering tasks. For senior engineers, this shifts the work from writing every line of code to setting direction, defining guardrails, reviewing outputs, and protecting critical areas like authentication, permissions, JWT flows, and security-sensitive logic.
It feels like another step toward the agentic software development workflow.









 Gemini 2.5
Gemini 2.5
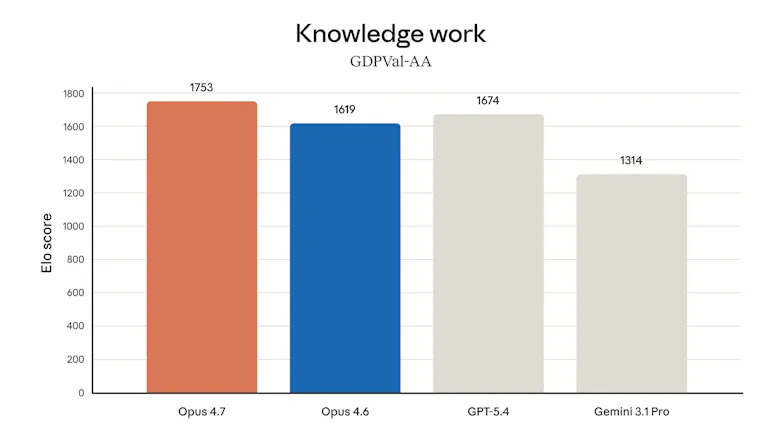
Claude Opus 4.7 looks like a serious leap forward for AI-powered development and knowledge work. It tackles a key problem: handling complex, long-running tasks that previously required constant human supervision.
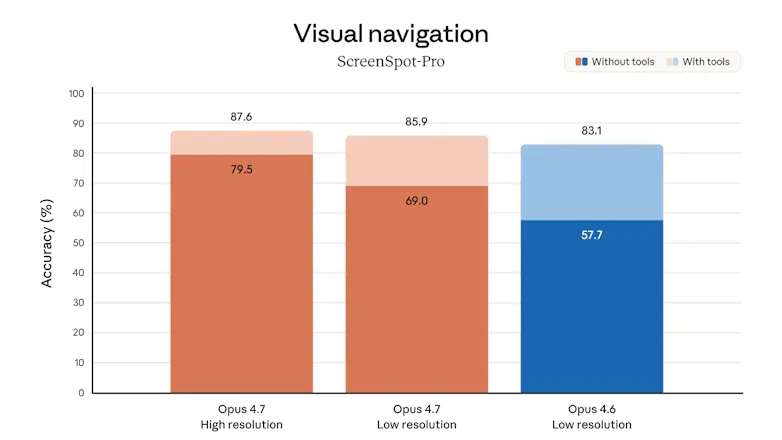
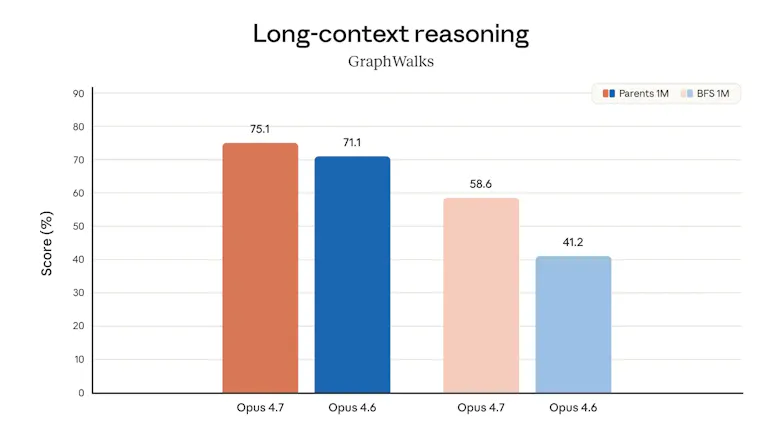
With stronger instruction-following, better multimodal vision, and improved reasoning consistency, it enables users to confidently delegate harder workflows.
Why it stands out:
Verifies its own outputs for higher reliability
Maintains coherence across long, multi-step tasks
Improved high-resolution image understanding
Better memory across sessions for ongoing work
Key features:
Advanced coding + agentic task handling
`/ultrareview` for deep code reviews
Effort control (high → xhigh) for better reasoning vs latency tradeoff
Available across API, Claude apps, and major cloud platforms
Who it’s for & use cases:
Developers building AI agents and automations
Analysts working on finance, research, and modeling
Teams handling complex docs, workflows, and long-running tasks
If you’re building AI agents or scaling complex workflows, this feels like a meaningful upgrade.
P.S. I hunt the latest and greatest launches in tech, SaaS and AI, follow to be notified → @rohanrecommends
Kilo Code
to quote @leerob: "I really like this model for general agentic work outside coding. It is definitely expensive though."
a product like @Edgee might be a great combo in this context imho
been running Opus 4.7 in Claude Code for the past couple days and the agentic stuff is noticeably better than 4.6. it actually follows through on multi-file refactors without losing context halfway through which was my biggest complaint before. the effort control slider is nice too — i keep it on high for architecture work and drop it down for quick fixes. only gripe so far is the adaptive thinking sometimes skips reasoning on queries it probably shouldn't, but overall it's a solid step up for daily coding work
The session memory improvement is the feature I've been waiting for. Working on a large codebase with Claude Code, the biggest pain was re-explaining architectural decisions every new session. If Opus 4.7 actually retains context across multi-session projects, that alone justifies the upgrade. Curious how the new tokenizer affects costs in practice — 1.35x more tokens on the same input is worth watching.
@ethanfrostlove Same, I ended up upgrading from Pro to Max and still faced those limitations (at least to an extent) but what I've been doing to circumvent that issue is by paying attention to the context cap. When there's 5% left I ask it to commit everything in the last hour or so to memory and have memory exported to a location of my choice.
When the context windows is maxed out and compacting or I simply start a new conversation I'll point Claude to that memory bank and tell it to continue where I left off. This seems to work fluidly for me.
Open Wearables
the verification step is interesting. most models just output and hope for the best. how does Opus 4.7 actually verify its own code outputs - static analysis, test generation, or something else?