Legal AI that reads your documents
and knows the law.
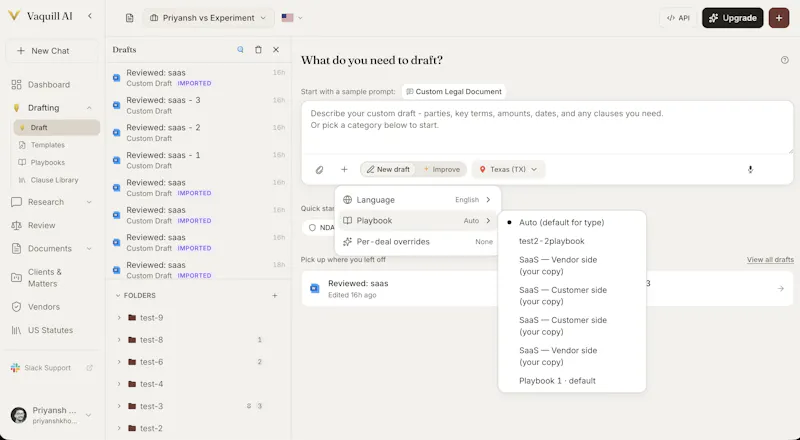
Ask a legal question, review a contract, or search thousands of your files. Every answer shows where it came from.
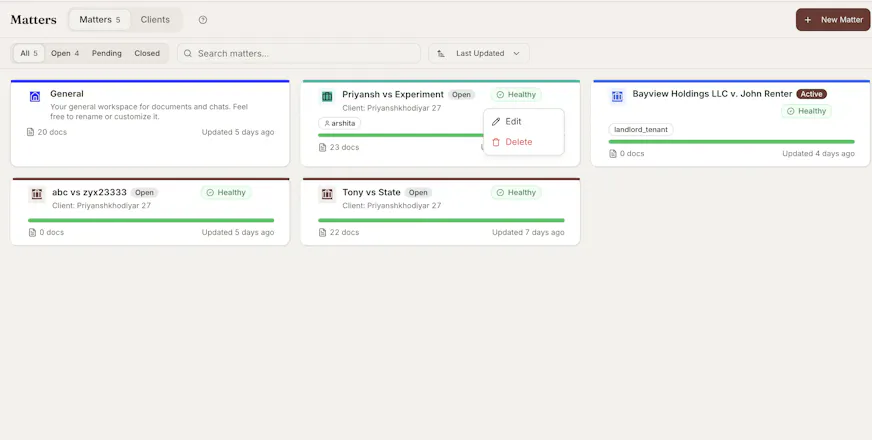
Contract review, compliance, drafting, document comparison, and matter management on one surface, built on the real Vaquill AI product your team uses every day.