Launching today

discode.ai
100+ AI models, one interface. You set the rhythm.
118 followers
100+ AI models, one interface. You set the rhythm.
118 followers
discode is your EU-friendly AI router: one interface for 100+ models, with every prompt auto-routed to the best one for the job. Or fine-tune it yourself along Smarter, Speed and Eco. It shows you which model answered and why, redacts your personal data on-device before anything leaves, checks the hard answers across multiple models, and estimates the CO₂, water and energy footprint of every request. Built in Vienna 🇦🇹. Your AI, your rhythm.






discode.ai
Hey makers!
I'm Pete from discode, thanks for checking out our launch.
discode is an EU-friendly AI router that turns 100+ models into one interface.
Every prompt gets auto-routed to the best model for the job, or you fine-tune it yourself along Smarter, Speed and Eco.
The part I'm most excited about is Eco.
Every AI answer burns electricity, water and CO₂. Most AI tools don't put that bill in front of you. discode shows CO₂, water and energy for every request – across 100+ models.
So a one-line summary might fire up a frontier model: driving the van to the ice-cream shop around the corner when a bike would've done.
🌱 Every answer shows a readout: CO₂, water, energy.
🚲 Eco-Routing by default picks the most frugal model that can handle your task. 60–70% of requests run in the most efficient tier.
🎚️ An Eco-Slider from 1 to 5 lets you push discode toward leaner models. You set the rhythm, not the algorithm.
It's a compass, not a measuring device: Honest estimates built on public research, which is why it's in beta.
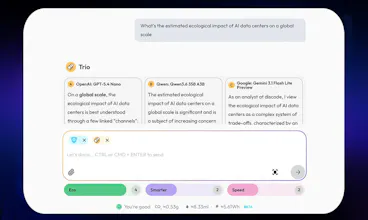
And there's plenty more under the hood: Challenger Mode (a different model reviews every answer), Trio Mode (3 models, one question, blind-judged), and on-device privacy filtering that redacts personal data before anything leaves your machine.
Built in Vienna 🇦🇹, for everyone who'd like their AI to not cost the planet more than it has to.
Would love your feedback <3
The Eco framing is the fresh part here, most routers sell speed and cost and stop there. One thing I keep wondering about with auto-routing. Deciding a prompt is hard enough to fan out across multiple models is itself a judgment call, and getting it wrong either wastes the eco budget or under-serves a real question. How is that difficulty call made, and how do you verify after the fact that the cheaper or greener route actually matched what a frontier model would have answered?
discode.ai
Great question, you've put your finger on the exact tension, and we take it seriously.
First, the difficulty call. Selection runs on domain, speed, cost and eco together, bounded by where you've set your Turntables (Smarter, Speed, Eco). The domain benchmark does a lot of the work, since a coding question and a casual translation have very different model requirements; we route within four tiers, so light tasks stay cheap and low-footprint while harder ones escalate to specialists or frontier models. On top of that we classify every prompt for complexity, output shape and task type, plus a few other signals. I'll be honest about where that stands: those signals are captured and stored against actual outcomes, but not all of them are live routing inputs yet. We're building the calibration dataset first, so that when they do shape selection, the thresholds come from real data rather than intuition. Two things keep it honest in the meantime: every answer shows which model ran and why (no black box), and when the routing misses, your feedback flows straight back into the model choice. The tiers aren't static either: a nightly sweep re-scores all 100+ models on fresh benchmarks, pricing and real user signals.
On verification, I'll be straight with you: we don't claim to know what a frontier model "would have said." There's no crystal ball that runs for free, no oracle, and you can't check that without running the frontier model yourself, which burns the eco budget you just saved. So no phantom comparison. What we do instead is measure: every routed response persists its actual token count, energy and cost next to the complexity classification. The plan is to bucket those outcomes by model, mode and task type, and only let a finer routing rule promote itself if it measurably reduces prediction error without increasing context overruns. Challenger already produces side-by-side quality comparisons; wiring that quality signal into the calibration loop is the next step.
And for the here and now, when truth actually matters you switch on the multi-model check. Trio sends your question to three models from three different provider families; a separate judge scores them blind and in random order, merges the best, and flags where they disagree. Challenger goes the other way: a different family takes one answer apart and rebuilds it over a few rounds. Different families have different blind spots, so what one invents, the others usually catch.
It cuts errors hard, but it doesn't zero them. You stay the judge. Happy to go deeper on any piece.
Mo
The on-device PII redaction before anything leaves is the part most AI routers skip - model routing and cost views are everywhere, but client-side redaction is what actually makes this safe to put in front of a team. My one concrete worry: when a name or ID gets redacted but is needed for the current answer and was first mentioned 10 messages back, does it consistently re-mask the same entity to the same token across the thread so the model still gets coherent context, or can it lose that reference once it is stripped?
discode.ai
@hazy0 You're zeroing in on the exact thing that makes naive redaction useless: black out a name and the model loses the thread - coreference breaks, the answer turns incoherent.
So we don't black anything out, and you don't have to hunt for the sensitive bits yourself. A local assistant does that on your device, before anything leaves: pattern matching catches the structured stuff (email, phone, IBAN, cards), and a small model running in your browser catches names, companies and places. It surfaces every find and proposes what to anonymize; you approve or override per data point. The assistant does the work, you keep the decision, and nothing is uploaded just to detect it. That is what makes it safe in front of a team: nobody has to catch every name or IBAN by hand before hitting send.
Each detected entity is then swapped for a realistic look-alike, and that stand-in is baked into the conversation history that travels with every request. When something introduced 10 messages back is needed now, the model reads the same consistent stand-in from that history - a coherent conversation of plausible people, not a wall of [REDACTED]. You see your real values; the model only ever sees the stand-ins.
That real-to-stand-in map lives only on your device, in your browser - never logged, never in our database, never sent to our servers. That's also why the next edge exists at all.
Honest edges: detection isn't perfect (rare spellings, or an identity that only emerges from combining several harmless details); the map is device-local, so ask on your phone and open the thread on your laptop and you'll see stand-ins there; and restoration is a literal match, so if the model reformats a stand-in - abbreviating "Street" to "St.", changing case, inflecting a name - that spot can show the plausible stand-in instead of your real value. That last one is cosmetic, never a leak: the unrestored text is the fake, and your real value never left your device.
The eco-slider is interesting! Wondering...When the frugal tier under-serves a hard prompt and I re-ask, that retry probably burns more than just hitting a frontier model once? Does a re-ask count against the eco budget? Showing which model answered and why is the right call regardless!
discode.ai
@artstavenka1 Hi Art, you've put your finger on two of the things we care about most, and the transparency you mentioned, showing which model answered and why, is deliberate for exactly this situation.
On the honest part: yes, a re-ask counts. Every attempt is metered, in cost and in CO₂, water and energy, so on a genuinely hard prompt a couple of tries can outweigh a single direct call. We don't pretend otherwise, and that visibility is the point: you get to see it and decide, rather than us quietly spending more on your behalf.
Where we're headed is smarter about this: escalation that can bump a weak first answer up a tier without a full manual retry, and folding your retries back into routing so the system learns from them. The data for both is already being logged, so it's a matter of wiring it through. Thanks for the nudge, this is exactly the kind of feedback that shapes what we build next.
Is there a way to bring our own API keys for specific models if we already have corporate credits, or is everything managed through a unified discode subscription tier? congrats for shipping @peterbuch 👏
discode.ai
@priya_kushwaha1 thanks Priya, that's a great question. There currently isn't any way to bring corporate credits to discode, but that's certainly something we are looking into.
Happy to chat more, if you have more feedback, thanks again for your support.
The Eco routing angle is genuinely interesting but I'd love to know how the difficulty classification works upstream. If the routing decision itself runs on a heavyweight model every time, does that overhead cancel out the savings on simpler queries? Curious if you've benchmarked the router's own footprint.
discode.ai
@vishal_thakor9 Hi Vishal, great question, and exactly the one that would sink the whole idea if we got it wrong.
The router doesn't run on a heavyweight model, and on simple queries it often runs no model at all. It works in two stages: a fast pattern-matching pass reads the domain, language and locale for zero tokens, and a lot of straightforward queries are fully sorted right there. Only when that pass isn't confident does a small classification model step in, and even then it's a tiny call, cached so repeats and near-repeats cost nothing. The routing decision is then frozen for that request, so we never route the same thing twice.
On whether we've measured it: yes. We log each classifier call on its own, so the router's footprint is something we can read directly rather than hand-wave. In practice it's a tiny call set against the savings of keeping a simple request on a lightweight model instead of a frontier one, so the overhead is a rounding error next to that. And the classifier's own cost sits on our side as infrastructure, not on your bill.
One honest nuance: difficulty alone doesn't pick the model. It feeds a tiered score across domain benchmarks, speed, eco and price, weighted by where you've set your sliders, so the classifier informs the decision, it isn't the decision. Happy to go deeper if that's useful.
Mo
discode.ai
Hey everyone, Moriz here, the one who started this whole disco. 🪩
Quick confession: I can't code. My last brush with it was an HTML course in the late 90s, and I'm part of a coffee-house project in Vienna. So, very much not a techie. A few months ago I got stuck on questions nobody seemed to be building for:
What does AI cost the planet, and how do you let people see it, steer it, and weigh the trade-offs without guilt?
AI is confidently wrong. What does honest uncertainty look like when reliability matters?
When a doctor or lawyer uses AI, their patients and clients are exposed, usually without anyone noticing. Why isn't privacy the default for ordinary people, not just an enterprise feature?
So I went down the vibecoding rabbit hole. The irony isn't lost on me: using Claude Code to build something meant to be more responsible than Claude itself. Three Claude Max subscriptions and $2,000 in API tokens later, my first version was a glorious 417,000-line monster. After countless night shifts and weekends next to the day job, I understood I'd need real pros to ship this. A small crew of engineers and designers then carved that monster into something beautiful that actually works. Thousands of hours and a lot of love and creativity went into it. Thank you, all of you. (We're hoping to earn that carbon back, too.)
Pete already gave you the what: the routing, Eco, Challenger, the on-device privacy filter. So let me give you the why.
The race everyone's running is about who has the biggest model, who has the biggest... data centers, who has the biggest IPO. We want to open a different one. Not how AI gets more powerful or how you get rich off it, but how we build the best interface between people and these machines, so they serve us, and so Europe is more than the raw material quietly feeding them our data. Pro-European, not anti-American. I don't think we should only consume what others build.
We're nowhere near done. The Eco score is a first step, which is why it's in beta. discode is a lab and a playground for human-centered AI, and it gets better with you in it. So please: tell us what's broken, what's missing, what you'd do differently. And if we ship your idea, there are discode credits in it for you. Every honest note steers where this goes. 🙏
You choose the rhythm, not the algorithm.
Mo
discode.ai
@mo_riz it's been a great pleasure working on this mission with you and the team.
Let's go!