
NeoSmith AI
Custom SLM for AI Agents: 40–55% cheaper, 3–5x faster
4 followers
Custom SLM for AI Agents: 40–55% cheaper, 3–5x faster
4 followers
Neosmith trains a custom Small Language Model from your LLM interaction logs. The SLM handles 80–90% of agent tasks at 40–55% of the cost and because it's trained on your workload, accuracy goes up too. One endpoint swap. No MLOps.








Hey PH 👋 Udit here, co-founder of NeoSmith.
Quick story on why we built this.
I was watching teams spend $40k/month running GPT-5 on workflows that did literally one thing: extract structured data from documents. Same input shape. Same output shape. 50,000 times a day.
Nobody wanted to fix it because "fine-tuning takes months and we don't have the dataset."
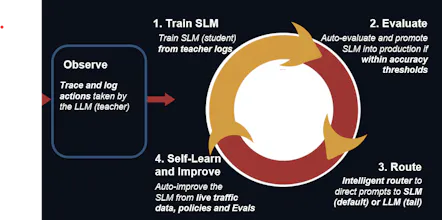
That's the problem NeoSmith solves. Your production traces ARE the dataset. We just read them.
The simplest way to explain what we do:
Point your LLM to ours. That's it.
NeoSmith watches your existing workflow, reads your production traces, and automatically creates a dedicated Small Language Model for your exact task. No dataset. No labeling. No fine-tuning work from your side. You wake up with a purpose-built model that does your job at a fraction of the cost.
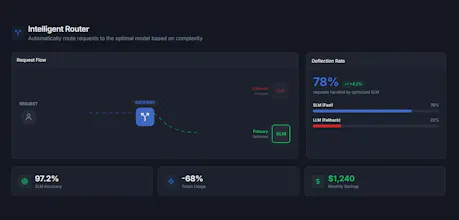
What changes after: 70% lower inference cost. 3x faster. And here's the part that surprises most people: accuracy goes up.
On accuracy, because this is where it gets interesting:
GPT-4 is a generalist. It knows everything, which means it's also distracted by everything. When you ask it to classify a support ticket, part of its brain is still thinking about writing poetry and solving calculus.
Your distilled SLM knows one thing: your workflow. It has been trained exclusively on your real production traffic, your actual input patterns, your expected output format. It has never seen anything else.
That specialization wins. On narrow repetitive tasks we see accuracy go above the frontier model baseline, not just match it. The SLM stops hedging. It stops over-explaining. It gives the precise output your downstream system expects, every time.
We run a full accuracy report before you switch a single request. You see the exact delta. You see where it wins and where the edge cases are. In most cases teams are surprised the smaller model outperforms the frontier model on their specific task. It sounds counterintuitive until you think about what specialization actually means.
And it keeps getting better automatically. Every new trace feeds back into the next distillation cycle. The model improves continuously as your workflow evolves.
We're looking for 3 design partners right now.
Completely free. We are not selling anything. We want to work closely with real teams on real workflows and prove this out together.
What we need from you: just point us at your existing observability tool (Langfuse, Helicone, Portkey, whatever you use) and jump on a 30-minute call.
What you get back: a working SLM created specifically for your workflow, a full before/after report on cost, latency, and accuracy, and an honest view of where it wins and where the edge cases are.
No contract. No pitch. No ask at the end. We just want to solve this with you.
You're a fit if: ✓ You have agents running in production, not a demo ✓ Your LLM bill is growing and you've noticed it ✓ Your workflow does something repetitive: triage, extraction, classification, routing, structured generation
Comment below or DM me directly. I'll respond to every message personally today.