
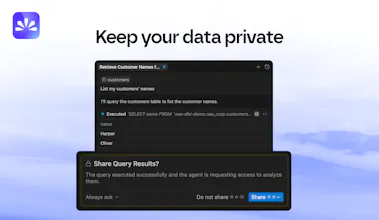
Nao is an AI powered data IDE for analysts, engineers, and scientists to write SQL, Python, or dbt workflows, preview changes, catch issues early, and deploy confidently. It connects directly to your warehouse and understands your schema so you can build faster, fix fewer bugs, and maintain trust in your data. Build data pipelines, launch quality checks, run analytics, and collaborate across teams without context switching. Think of it as your AI teammate built specifically for modern data work.





Free Options
Launch Team / Built With






















nao
Thank you for your review Chau, that's very great to read! We're working on a way to make nao even better for exploration and analytics. Stay tuned!