Launched this week

Vouch
ai, agent
8 followers
ai, agent
8 followers
Vouch is durable, review-gated decision-memory for Gittensor (Bittensor SN74): a cited knowledge base that records why each scoring rule, allow-list, and emission-split decision was made — and what it superseded.


How does Vouch actually get the gating right so a decision can’t be added without enough qualifying reviews, and is that threshold something validators set themselves or is it fixed at the protocol level?
@asiyel42174 Hey, thanks for taking the time to dig into vouch — this is a great question.
So there's actually no voting or validator threshold in vouch at all — I think you might be picturing something more blockchain-y than it is. It's just a local knowledge base with one rule: nothing gets written without a review.
The way it enforces that is pretty simple. There's exactly one function that can turn a proposal into an accepted entry, and every interface (MCP, CLI, everything) has to go through it. That function checks the proposal is still pending, validates it, writes it, and logs the event to an append-only audit log. There's no side door — the storage layer has no logic of its own, so nothing can sneak a decision in around the gate. And since the whole KB lives in git, if someone hand-edits the files to fake an approval, it shows up in the diff with no matching audit entry. Easy to spot.
The "threshold" is just: one approval, from someone who isn't the proposer. That's hardcoded — there's no way to configure "require 3 reviews" or anything like that. The only setting that exists goes the other way: solo users can flip a config flag (trusted-agent) to allow self-approval, since otherwise you'd be stuck reviewing your own proposals with nobody else around. So you can loosen the gate for yourself, but you can't remove it or raise it without changing the code.
Happy to go deeper on any of this if you're curious — and if you end up trying it out, I'd love to hear how it goes.
The idea of tying every scoring rule or emission change to the previous one it replaced is genuinely clever, makes the whole governance trail actually legible instead of buried in forums.
@muzafferkug1d4 Thanks, that's exactly the property I was chasing. The frustrating thing about how most projects govern changes is that the current rule is written down somewhere, but the story of how it got that way is scattered across forum threads and chat logs — so six months later nobody remembers why the old version was abandoned, and the same debates get relitigated from scratch.
In vouch that history is structural, not archival. When a new claim supersedes an old one, the link is written in both directions — the old entry gets marked superseded and points at what replaced it, the new one points back at what it replaced — and the old claim never gets deleted, just retired. Swapping a rule out also goes through the same review gate as adding one, and the reason for the replacement gets recorded at that moment, while it's still fresh. So you can grab the current scoring rule and walk the whole chain backwards: what it replaced, what that replaced, and why, each step reviewed and dated.
Your emissions example is honestly a perfect fit for it. A subnet's scoring and emission parameters change constantly, and today the audit trail for that is basically "scroll Discord." A KB where every parameter change has to supersede the previous one — with a stated reason and a reviewer's sign-off — would make that whole trail greppable. If you end up trying it for that, I'd genuinely love to hear how it holds up.
Hey Product Hunt 👋
Every persistent-memory tool for AI agents makes the same trade: the agent writes its own history, an LLM compresses it, and whatever it decided gets injected straight back into the next session. Nobody reviews it. If it hallucinated a "fact" on Monday, it's confidently citing itself by Wednesday.
vouch takes the opposite bet: memory should go through review, like code does.
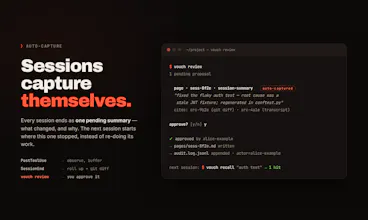
One rule: every write passes a gate. The agent proposes a claim, you approve it, and only then does it become durable. Approved knowledge is plain YAML and markdown inside .vouch/ in your repo — so git is your audit log, PRs are your review UI, and the whole KB diffs cleanly.
What ships today:
🔒 Review gate — agents can't approve their own writes; try it, the server refuses
📎 Citations enforced — a claim without a source is a validation error, not a warning
🪝 Auto-capture — Claude Code hooks harvest each session into one pending summary, mechanically (no LLM), never auto-approved
🧠 Recall — the next session starts from what you approved, not from cold
🔌 MCP + JSONL + CLI — same surface for Claude Code, Cursor, Codex, and humans
📜 Append-only audit log — "which agent claimed what, citing what, when" for free
It's for teams where multiple agents share a repo, where sessions keep re-explaining the same context, or where you'd review an agent's claimed facts the way you review its code. (Gittensor SN74 miners: there's a template that seeds the scoring baseline — vouch init --template gittensor.)
Local-first, plain files, MIT, on PyPI:
`pipx install vouch-kb`
Still alpha and the surface is small on purpose. I'd love to hear where the review gate helps you — and where it gets in your way.
https://github.com/vouchdev/vouch
The idea of attaching citations directly to every scoring rule is genuinely useful, and seeing the full history of what each decision replaced makes governance audits way less painful.
@enay1933563 Thanks for checking
finally a way to actually track the why behind scoring changes on Bittensor, the citations make it way easier to follow governance decisions without digging through discord threads