Gemini 2.5 Flash
Fast, Efficient AI with Controllable Reasoning
5.0•26 reviews•1.3K followers
Fast, Efficient AI with Controllable Reasoning
5.0•26 reviews•1.3K followers
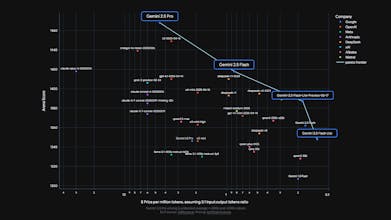
Gemini 2.5 Flash, is now in preview, offering improved reasoning while prioritizing speed and cost efficiency for developers.