
Context.dev gives your AI agents and apps real-time access to structured web data, no brittle scraping infrastructure needed. Scrape any URL as clean markdown or HTML, extract brand data (logos, colors, fonts, socials) from any domain, crawl sitemaps, resolve transaction descriptors, and more. Typed SDKs for TypeScript, Python, and Ruby. Trusted by 5,000+ businesses including Mintlify, Daily.dev, Ferndesk.com, and more. Most teams integrate in under 10 minutes.
This is the 2nd launch from Context.dev. View more
Context.dev
Launched this week
Context.dev is the web context API for AI products and agents. Scrape any URL, crawl sites, turn pages into LLM-ready Markdown, extract structured data into your own schema, capture screenshots, and retrieve logos, colors, fonts, styleguides, company data, and transaction enrichment through one API. YC-backed, no card required, and built so developers or coding agents can integrate in minutes.



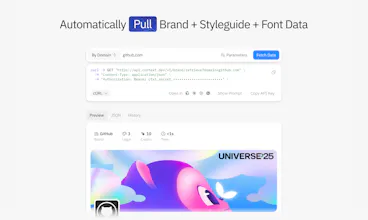

Free Options
Launch Team / Built With







Pricing tied to successful scrapes only looks useful! Paying for failed fetches could be painful, I know this from own experience. Curious on the stealth layer as plenty of sites serve completely different content by visitor country (price, availability, language)... Can I pin the exit region per request or does the geo just fall out of whatever proxy the pool grabs that day?
Context.dev
@artstavenka1 yep the country parameter is in there!!
Typed SDKs across TS/Python/Ruby plus sub-10-min integration is a great combo. Curious how you handle caching/rate limits when a customer wants to enrich brand data for thousands of domains in one batch - queued async or synchronous per call?
Context.dev
@dannyheng thousands is trivial, we only recommend calling us when you want to exceed 1K TPS or 60K requests/minute, all we have to do is one click to enable this for your account and it helps us forecast infrastructure demands!
Context.dev
@moh_codokiai Hey! We run constant quality checks on millions of requests daily and ship infra improvements 2x per day.
This is something we care about ALOT. Great question.
How does the brand data extraction actually work under the hood when a site uses lazy loading or dynamically renders its content client-side?
Context.dev
@melisao2k9 we use a near perfect custom browser, so doesn't matter if they use lazy loading or not! you can try it out now :)
How does it actually handle sites that load content dynamically with JavaScript, does it run a real browser under the hood or just hit the raw HTML and miss half the page?
Context.dev
@tahsincceuqp4 every single request goes through a browser. JS is always assumed to be there, we've found anything less affects quality dramatically.
Spent a few minutes pulling structured data from a couple of sites and it just worked, no fiddling with selectors. The brand extraction endpoint was a nice surprise, saved me wiring up a separate service.
Context.dev
@idemx532 we have a relentless focus on quality + cost efficiency.
The goal is, we're always cheaper than if you try to stitch together an in-house solution, and always higher quality than ANY other competitor.
We are 1s slower on avg than other competitors, but for the tradeoffs mentioned, it's never been a blocker.
Nice work! The UI looks clean. I'm curious, what was the biggest challenge while building this?
Context.dev
@kian_1602 Everything. Maintaining stable infrastructure is a huge huge headache, we got it right and need to make sure we continue to deliver as we scale a ton more.
Context.dev
@kian_1602 scaling fast, we use porter to deploy scalable infra so it works wonderfully.
Can handle 100K TPS if needed.