

ThriftyAI
Cut AI costs by 80% with intelligent semantic caching.
5 followers
Cut AI costs by 80% with intelligent semantic caching.
5 followers
Intelligent semantic caching for OpenAI, Anthropic & Google AI. Reduce costs by 80%, speed up responses 10x. Cross-provider cache, PII masking, automatic fallbacks.







Hi Product Hunt! 👋 I'm Bahadır, the maker of ThriftyAI.
Stop paying twice for the same AI answer!
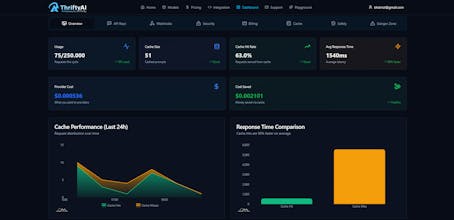
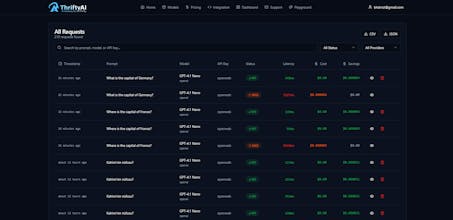
40% of production LLM traffic is the same question rewritten.
You pay again. You wait again. Pointless.
ThriftyAI sits between your app and OpenAI, Anthropic, or Gemini.
It caches by meaning, not just text — so repeated intent returns in <50ms instead of 2s.
The Result: Real API savings (teams cut costs by up to ~80%), instant responses, zero UX regression.
- PII redaction before any model sees data
- Automatic provider fallback (Never go down)
- API key budgets (Intern-proof)
Free tier: 10k requests/month. No card required.
If you’re shipping AI to production, ThriftyAI pays for itself in week one.
Let’s make AI cheap again. 🚀
I'll be hanging out in the comments all day to answer your questions!