

Prodigy
Radically efficient machine teaching
7 followers
Radically efficient machine teaching
7 followers
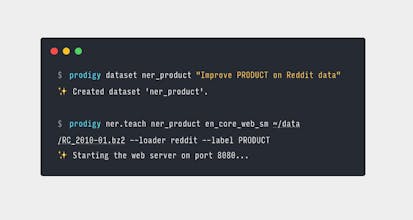
Prodigy is a new annotation tool for creating training and evaluation data for machine learning models. It comes with an extensible, self-hosted back-end, active learning-powered models that update as you annotate, and a modern web application that helps you stay focused.

Prodigy
CraftStrom
Prodigy
CraftStrom
Prodigy
Prodigy
Prodigy