Launching today

discode.ai
100+ AI models, one interface. ECO friendly.
475 followers
100+ AI models, one interface. ECO friendly.
475 followers
discode is your EU-friendly AI router: one interface for 100+ models, with every prompt auto-routed to the best one for the job. Or fine-tune it yourself along Smarter, Speed and Eco. It shows you which model answered and why, redacts your personal data on-device before anything leaves, checks the hard answers across multiple models, and estimates the CO₂, water and energy footprint of every request. Built in Vienna 🇦🇹. Your AI, your rhythm.






discode.ai
Hey makers!
I'm Pete from discode, thanks for checking out our launch.
discode is an EU-friendly AI router that turns 100+ models into one interface.
Every prompt gets auto-routed to the best model for the job, or you fine-tune it yourself along Smarter, Speed and Eco.
The part I'm most excited about is Eco.
Every AI answer burns electricity, water and CO₂. Most AI tools don't put that bill in front of you. discode shows CO₂, water and energy for every request – across 100+ models.
So a one-line summary might fire up a frontier model: driving the van to the ice-cream shop around the corner when a bike would've done.
🌱 Every answer shows a readout: CO₂, water, energy.
🚲 Eco-Routing by default picks the most frugal model that can handle your task. 60–70% of requests run in the most efficient tier.
🎚️ An Eco-Slider from 1 to 5 lets you push discode toward leaner models. You set the rhythm, not the algorithm.
It's a compass, not a measuring device: Honest estimates built on public research, which is why it's in beta.
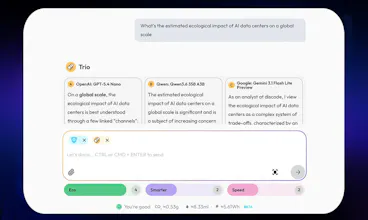
And there's plenty more under the hood: Challenger Mode (a different model reviews every answer), Trio Mode (3 models, one question, blind-judged), and on-device privacy filtering that redacts personal data before anything leaves your machine.
Built in Vienna 🇦🇹, for everyone who'd like their AI to not cost the planet more than it has to.
Would love your feedback <3
@peterbuch Love the eco angle, nobody frames model choice this way. The failure mode I'd worry about: eco-routing picks the frugal model, it under-delivers, the user re-asks or you retry on a bigger one, and now you've burned MORE CO2 than just starting with the right model. How do you avoid the cheap-first-then-escalate tax, predict task difficulty up front, or does that retry cost get hidden from the readout?
discode.ai
@david_marko David, thanks for the question.
real failure mode, and I won't dodge it. Let me be concrete.
We predict, then route, rather than run, judge and retry.
Every request is sized up front by a lightweight classifier (a fast pattern-matching pass first, then a small classification model only on genuinely ambiguous or longer prompts), and it runs once, before anything is picked.
The classification sets a floor, not just a ceiling: a prompt that reads as hard is held to at least a capable model from the start, even when your Turntables lean Eco, and if nothing capable enough fits the context, we fail closed rather than quietly run something too small. So "frugal model under-serves a hard task" is something we design out at selection time, not patch with a bigger second run.
There's also no silent auto-escalation. We never grade our own answer behind your back and re-fire on a larger model. The only multi-model paths are Trio and Challenger, and those are modes you choose and can see, never something that fires on its own. Any quality signal you see is for your eyes, so if an answer under delivers you can bump Quality yourself on the next pass. Us spotting that and nudging you proactively is the next step, not something I'll claim we already do.
Now the honest edge, because a classifier isn't an oracle: when the up-front read is wrong and you re-ask, that re-run isn't hidden. Every model call is metered from real provider usage and shown as its own footprint. So a misjudged hard prompt that needs a second pass shows its full cost, and yes, two passes can go net negative versus one direct call.
@peterbuch Congratulations to you and the team first for building and second for the launch. I completely know the amount of work and dedication that went into production to finish line. One question, most AI model have memory of user's activities or tasks. When multiple models are dispatched across a single task or conversation, how is memory and context handled? Does discode maintain a central context layer, or does each model only see what's passed to it at that moment?
discode.ai
@richatsealedvault Hi Richard — thank you, that really means a lot.
Great question. The way it works today: discode keeps a central context layer for each conversation, and every model involved works from that same shared context — so nothing gets lost when more than one model handles a task. As it stands, that context is the conversation itself rather than a separate stored profile.
Both sides of this are areas we're actively investing in — smarter ways to manage and stay in control of context, and persistent memory across conversations, are on our roadmap. The context-side improvements also help keep things efficient on the eco footprint.
Anything else I can answer for you?
@peterbuch Love that you're tackling the eco angle — how'd you measure the carbon footprint difference compared to hitting each API separately? That's a compelling angle most builders miss entirely.
The Eco framing is the fresh part here, most routers sell speed and cost and stop there. One thing I keep wondering about with auto-routing. Deciding a prompt is hard enough to fan out across multiple models is itself a judgment call, and getting it wrong either wastes the eco budget or under-serves a real question. How is that difficulty call made, and how do you verify after the fact that the cheaper or greener route actually matched what a frontier model would have answered?
discode.ai
Great question, you've put your finger on the exact tension, and we take it seriously.
First, the difficulty call. Selection runs on domain, speed, cost and eco together, bounded by where you've set your Turntables (Smarter, Speed, Eco). The domain benchmark does a lot of the work, since a coding question and a casual translation have very different model requirements; we route within four tiers, so light tasks stay cheap and low-footprint while harder ones escalate to specialists or frontier models. On top of that we classify every prompt for complexity, output shape and task type, plus a few other signals. I'll be honest about where that stands: those signals are captured and stored against actual outcomes, but not all of them are live routing inputs yet. We're building the calibration dataset first, so that when they do shape selection, the thresholds come from real data rather than intuition. Two things keep it honest in the meantime: every answer shows which model ran and why (no black box), and when the routing misses, your feedback flows straight back into the model choice. The tiers aren't static either: a nightly sweep re-scores all 100+ models on fresh benchmarks, pricing and real user signals.
On verification, I'll be straight with you: we don't claim to know what a frontier model "would have said." There's no crystal ball that runs for free, no oracle, and you can't check that without running the frontier model yourself, which burns the eco budget you just saved. So no phantom comparison. What we do instead is measure: every routed response persists its actual token count, energy and cost next to the complexity classification. The plan is to bucket those outcomes by model, mode and task type, and only let a finer routing rule promote itself if it measurably reduces prediction error without increasing context overruns. Challenger already produces side-by-side quality comparisons; wiring that quality signal into the calibration loop is the next step.
And for the here and now, when truth actually matters you switch on the multi-model check. Trio sends your question to three models from three different provider families; a separate judge scores them blind and in random order, merges the best, and flags where they disagree. Challenger goes the other way: a different family takes one answer apart and rebuilds it over a few rounds. Different families have different blind spots, so what one invents, the others usually catch.
It cuts errors hard, but it doesn't zero them. You stay the judge. Happy to go deeper on any piece.
Mo
discode.ai
@dipankar_sarkar thank you for your question, appreciate you.
The on-device PII redaction before anything leaves is the part most AI routers skip - model routing and cost views are everywhere, but client-side redaction is what actually makes this safe to put in front of a team. My one concrete worry: when a name or ID gets redacted but is needed for the current answer and was first mentioned 10 messages back, does it consistently re-mask the same entity to the same token across the thread so the model still gets coherent context, or can it lose that reference once it is stripped?
discode.ai
@hazy0 You're zeroing in on the exact thing that makes naive redaction useless: black out a name and the model loses the thread - coreference breaks, the answer turns incoherent.
So we don't black anything out, and you don't have to hunt for the sensitive bits yourself. A local assistant does that on your device, before anything leaves: pattern matching catches the structured stuff (email, phone, IBAN, cards), and a small model running in your browser catches names, companies and places. It surfaces every find and proposes what to anonymize; you approve or override per data point. The assistant does the work, you keep the decision, and nothing is uploaded just to detect it. That is what makes it safe in front of a team: nobody has to catch every name or IBAN by hand before hitting send.
Each detected entity is then swapped for a realistic look-alike, and that stand-in is baked into the conversation history that travels with every request. When something introduced 10 messages back is needed now, the model reads the same consistent stand-in from that history - a coherent conversation of plausible people, not a wall of [REDACTED]. You see your real values; the model only ever sees the stand-ins.
That real-to-stand-in map lives only on your device, in your browser - never logged, never in our database, never sent to our servers. That's also why the next edge exists at all.
Honest edges: detection isn't perfect (rare spellings, or an identity that only emerges from combining several harmless details); the map is device-local, so ask on your phone and open the thread on your laptop and you'll see stand-ins there; and restoration is a literal match, so if the model reformats a stand-in - abbreviating "Street" to "St.", changing case, inflecting a name - that spot can show the plausible stand-in instead of your real value. That last one is cosmetic, never a leak: the unrestored text is the fake, and your real value never left your device.
This is the right split — local detection with per-entity approval keeps a human in the loop without shipping raw text. The one thing I'd want for real team use: once I approve 'Acme → Client_A', does that mapping persist for the rest of the session so I'm not re-approving the same entity every turn, and on the way back does the local layer re-insert the real value into the model's answer so my team reads real names while the model only ever saw the token?
discode.ai
@hazy0 Great questions, and yes to both. Once you approve a mapping like "Acme → Client_A", it persists for the entire
conversation — no re-approving the same entity on the next turn. The mapping lives in your browser and gets reused
automatically whenever that entity comes up again.
And on the way back: yes, the local layer re-inserts your real values into the model's answer at render time. Your team
reads "Acme", the model only ever saw "Client_A". The server never touches the real-to-synthetic map — that stays on your
device, start to finish.
discode.ai
@hazy0 thanks for your question, let us know if you have any more feedback, thank you
Appreciate the detail Moriz. That four-tier domain routing bounded by the Turntables makes the upfront call legible, which is more than most routers offer. The piece I keep circling is the loop after the fact. When a tier under-serves and the user re-asks, does that signal feed back to recalibrate the domain benchmark, or is routing static per release? Closing that loop is what would turn this from a good router into one that actually gets sharper with use.
discode.ai
@dipankar_sarkar Great question, Dipankar, and you're pointing right at the gap between where we are and where we're headed.
It helps to split it into two loops, because they sit at different stages.
The nightly loop is live: a sweep re-scores the whole model catalog on fresh public benchmarks (coding, math and reasoning indices), current pricing, and aggregate usage. So which model wins inside a tier does shift over time. To be precise about the feedback point: that movement happens at the catalog level, not yet from your individual behavior.
The after-the-fact loop you're describing, a re-ask read as "this tier under-served me" and fed back to recalibrate the domain benchmark, is not closed yet. And I'd rather be straight than impressive here. We built the telemetry layer first: every routing decision is fully traceable, each answer is stored with its tier, the model that ran, your slider settings and your rating. The data foundation is solid. But that data doesn't drive selection scoring yet. The adaptive wiring on top is the next layer, not a shipped one.
What closing the loop looks like for us:
• Per-user affinity: if one model keeps earning top ratings on your coding prompts and another keeps missing, bias your future coding selections accordingly.
• Domain recalibration: enough low ratings on eco-routed math prompts raises the minimum tier floor for the math domain.
• Regen-cost awareness: when an eco route triggers a retry cycle that ends up costing more than a direct frontier call would have, surface it as a nudge ("your last few eco prompts needed retries, consider bumping Quality"). An eco route you have to redo isn't actually green.
So, honestly: today it's mostly static between catalog refreshes, with the telemetry already capturing exactly what the adaptive layer will need. You're describing precisely what comes next.
mo
discode.ai
@dipankar_sarkar thank you for your support & questions
discode.ai
@ariaxhan hey Aria, great question. It's one of the biggest challenges for us to make discode a success. It's also something that I cannot publicly share. Happy to talk more in a one on one chat if you'd like though. thanks so much for supporting our launch.
discode.ai
@ariaxhan dear aria, The routing uses a combination of domain-specific benchmark data from public sources and our own evaluation layer. Each query gets classified by domain — coding, math, legal, creative, etc. — and models are scored against the benchmarks that actually matter for that domain, not just one generic leaderboard.
On top of that, users steer with sliders for quality, speed, eco; so the "best" model is always relative to what you actually need right now.
As for keeping up: our model radar continuously screens for new releases and benchmark updates, so the catalog stays current without manual intervention. When a new model drops, it gets scored and ranked automatically — no waiting for the next release cycle. any more questions? feel free to ask thx
Austria 👋 Building AI in adjacent space (DTC ad generation) and the multi-model routing point lands hard. Used to force everything through one pipeline early on, outputs were always mediocre at one step. Different tasks need different models.
The Eco angle is the part nobody else is showing. Most users don't know that a 1-line prompt to GPT-5 costs more than 50 to a smaller model. Curious, do users actually shift behavior when they see the readout, or is it more of a conscience check?
discode.ai
@elias_motionfy Elias, great question, and totally agree. We have just launched into beta so we don't have much data on user behavior yet. We certainly hope though that we can bring actual change in behavior. Do you think that's possible?
discode.ai
@elias_motionfy Hey Elias, grüß dich! Always good to hear from someone in the Austrian AI scene. And yeah — forcing everything through one
pipeline is the expensive version of learning that lesson.
On your question: honestly, too early to say with certainty. What we do see is that the transparency itself changes the
conversation. Once people realize their one-liner just cost 50x what it needed to, most don't need a second nudge — they
let the router do its job. Whether that's behavior change or just trusting the system to be frugal for them, the outcome is
the same: less waste, better fit. But we'll know more once we have real usage data at scale.
Thanks Moriz, splitting it into two loops is the right framing. The nightly catalog sweep keeps the model rankings honest, but that is recalibrating which model wins a tier, not whether the difficulty classifier put the prompt in the right tier in the first place. A re-ask is a free label there: an escalation event saying this domain was under-tiered. Even aggregated rather than per-user, feeding those escalations back into the per-domain thresholds is what would actually tighten the eco budget over time. Is that the second loop you mean, or is the nightly sweep doing double duty for now?
discode.ai
dear @dipankar_sarkar Spot on, and no, the nightly sweep isn't doing double duty: it recalibrates which model wins within a tier, not the tier boundaries themselves. The second loop you're describing doesn't exist yet. A re-ask today is just another request, not yet a correction signal. Re-asks as free labels for "this domain was under-tiered" is exactly the right framing, and the version worth building first. Thanks for sharpening that. thx