
Launched this week

Autotune
Run local LLMs faster and smoother on your device
23 followers
Run local LLMs faster and smoother on your device
23 followers
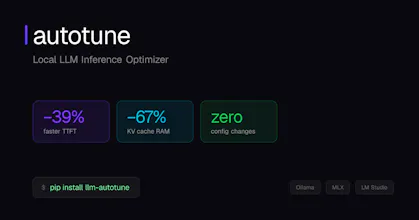
Autotune is an open-source runtime optimizer for local LLMs that reduces KV cache memory, improves first-token latency, and dynamically adapts inference settings to your hardware and workload. It works with Ollama, MLX, and as an API. Results from benchmarks show that Autotune can lower time-to-first-token by 39%, wall time for agentic workflows by 46%, and KV cache memory usage by 67%. Features include an OpenAI-compatible local API, a built-in CLI, RAM management, and model recommendations.
Hi everyone 👋
I was building and using software that utilized local large language models and my computer would often freeze or I would have to wait forever for the output. I wanted something that ensured that the model would be stable and fast on MY computer. That’s why I built Autotune.
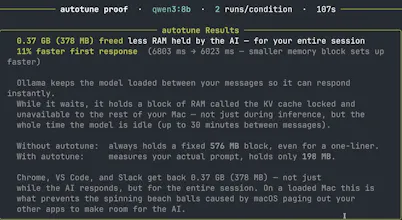
Autotune is a free runtime optimization layer that sits between you and your local model. It employs a handful of optimizations to ensure that the model running on your computer works as well as it can. These optimizations include precise KV cache allocation, dynamic RAM pressure management, system prompt prefix caching, smart context reduction, hardware-aware model recommendations, and more.
What this means for you is faster response times (especially for agents!), less computer struggles, and more RAM for all your other apps.
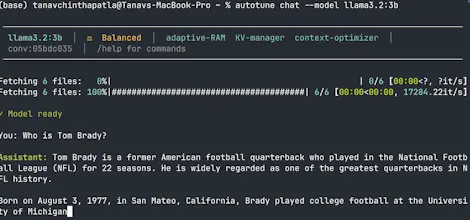
Works with Ollama, MLX, and as an OpenAI-compatible API.
I’ve spent a bit of time working on this so it would mean a lot to me if y’all checked it out - I think it can help you.
Thanks everyone!
RiteKit Company Logo API
@tanavc This addresses a real pain point for anyone running local models—the performance cliff is frustrating. The KV cache and RAM management optimizations sound particularly useful for keeping systems responsive. Have you noticed different optimization priorities depending on whether people are running agents versus single-turn queries.