

AI Search Index
Track which AI bots crawl your website
10 followers
Track which AI bots crawl your website
10 followers
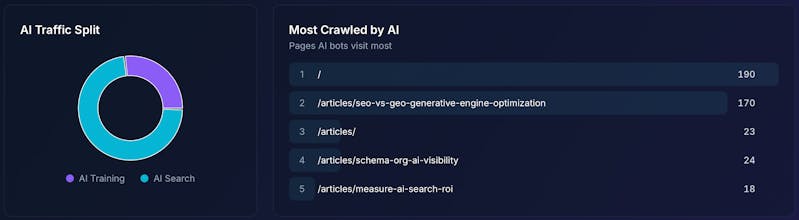
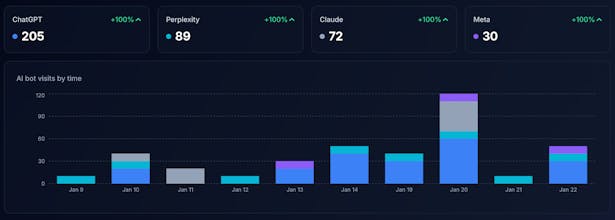
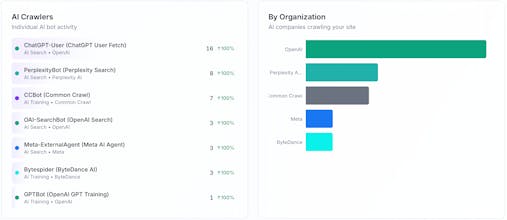
AI Search Index is the easiest way to see exactly which AI bots are reading your content, which pages they visit most, and how that traffic is growing over time. What you get: - Track 50+ AI crawlers by name (GPTBot, PerplexityBot, ClaudeBot, and more) - See which pages AI agents find most valuable - Understand the split between AI Search vs AI Training traffic - Chat with your data using our AI assistant All in one line of code.
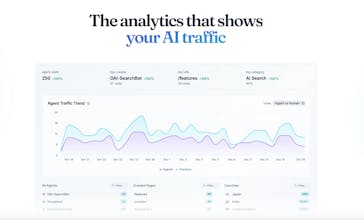
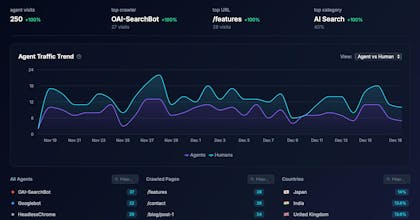
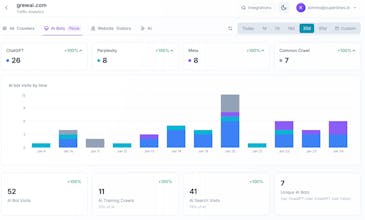
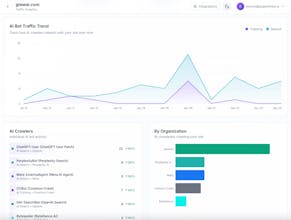



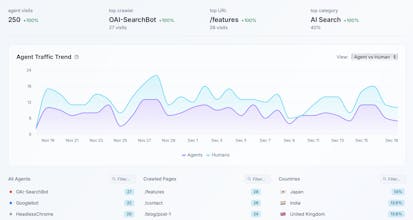
Superlines AI Search Analytics Platform
@ihmissuti congrats on the launch! Do you also provide content suggestions based on AI crawlers activity?
Superlines AI Search Analytics Platform
interesting concept! one question though , most ai crawlers don't execute javascript, they just fetch raw html. how does a js-based pixel detect them? wouldn't server-side log analysis be more reliable for bot detection?
Superlines AI Search Analytics Platform
@topfuelauto Yes you're absolutely correct that most AI crawlers don't execute JavaScript. This app uses a “hybrid approach” so we also have support for server-side log analysis for more robust method for capturing non-JS bots. So the app has multiple server-side log ingestion endpoints that bypass JS entirely and endpoints receive raw HTTP access logs from CDNs and hosting providers. The bot detection logic then analyzes:
User-Agent strings - 78+ LLM training bot patterns, 67+ LLM search bot patterns
IP ranges - Known CIDR blocks for OpenAI, Anthropic, Perplexity, Mistral
HTTP signatures - Signature-Agent header for signed ChatGPT agents
But we’ve learned that sometimes a simple solution is good enough to start capturing data, and here comes the JS pixel that primarily catches things like:
ChatGPT web browsing, actually executes JS via headless browser
Other AI agents that browse like humans (Claude's computer use, etc.)
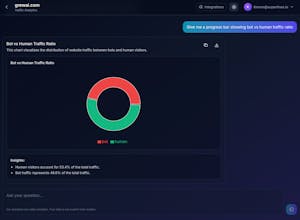
Human visitors - for comparison metrics
The "critical inline pixel" is designed for "fast bots" but honestly won't help with 100% of the crawlers.
The JS pixel is essentially a fallback for:
Users who can't/won't set up log forwarding
Catching the subset of bots that do execute JS
And there are of course some website platforms that make server side log access impossible or at least difficult (ping Webflow?)