

AgentAudit
The "Lie Detector" API for RAG & AI Agents
4 followers
The "Lie Detector" API for RAG & AI Agents
4 followers
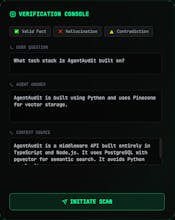
Stop AI hallucinations. AgentAudit is a middleware API that acts as a semantic firewall for your agents. It intercepts LLM responses and verifies them against the source context in real-time. Catch silent failures before they reach your users. Built with TypeScript & pgvector.

Swytchcode
Amazing. How do you detect the hallucinations when LLMs answer so confidently (except when they don't find a context and says sorry)
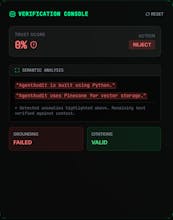
@chilarai That is exactly the tricky part since confidence scores are notoriously unreliable. Instead of relying on the model's tone, it perform a semantic proximity check. It vectorize the generated answer and mathematically compare it against the retrieved context chunks. If the semantic distance is too large meaning the answer drifts away from the source material. it flags it as a hallucination, no matter how confident it sounds.
Swytchcode
@jakops88_hub Really interesting. How much time does the API take to validate that? And also does it provide a score
@chilarai It typically adds about 200-400ms of latency right now, primarily due to the embedding generation step. The vector comparison in Postgres is nearly instant.
However, i am working on support for local embedding models (ONNX), which would bring this down to sub-50ms. Also, for non-critical use cases, i recommend running it asynchronously (fire-and-forget) so the user doesn't feel any delay at all.
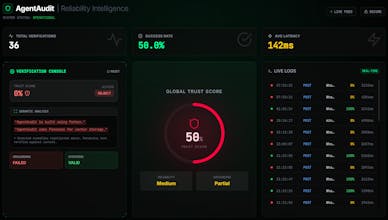
And yes, it returns a detailed JSON object with a specific Trust Score (0.0 - 1.0), so you can define your own strictness thresholds!