
Seed1.5-VL
Advanced vision-language AI for reasoning & agent tasks
7 followers
Advanced vision-language AI for reasoning & agent tasks
7 followers
Seed1.5-VL by ByteDance Seed is a new vision-language foundation model for general-purpose multimodal understanding, reasoning & agent tasks. Achieves SOTA on 38/60 benchmarks.












Flowtica Scribe
Hi everyone!
The ByteDance Seed team has launched Seed1.5-VL, a new vision-language foundation model for broad multimodal understanding and complex reasoning. There's a demo live on Hugging Face Spaces today, and the model is accessible via API on Volcano Engine.
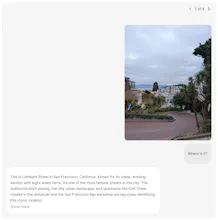
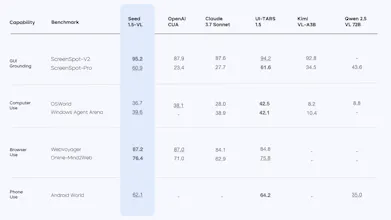
Seed1.5-VL shows impressive versatility: it's strong on visual and video understanding, achieving SOTA results on many benchmarks, and also excels at complex reasoning like visual puzzles and practical agent tasks such as GUI control.
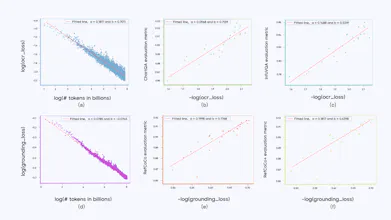
It's built with an efficient vision encoder and a Mixture-of-Experts LLM, trained on a massive 3 trillion token dataset. The team has released a technical report for a deeper dive, and the GitHub repo offers a cookbook for using the API.