
Step-Video-T2V
Open-Source, 204-Frame Video Generation from Text.
10 followers
Open-Source, 204-Frame Video Generation from Text.
10 followers
Step-Video-T2V is the open-source text-to-video model series from StepFun. Up to 204-frame generation, high compression Video-VAE, and video-based DPO for enhanced quality. Achieves SOTA on Step-Video-T2V-Eval.





Flowtica Scribe
Hi everyone!
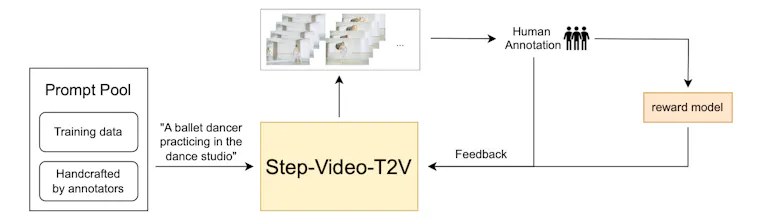
Sharing Step-Video-T2V, a new open-source text-to-video model from StepFun, one of the original top 6 AI model players in China. It's pushing the boundaries of video generation, achieving state-of-the-art results and offering some impressive capabilities:
Key Features:
🎬 Long-Form Generation: Can generate videos up to 204 frames long.
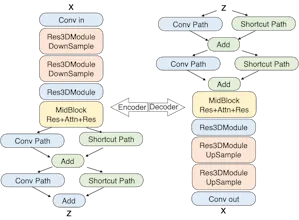
⚙️ Advanced Architecture: Uses a DiT (Diffusion Transformer) with 3D full attention.
⏩ High Compression VAE: A custom Video-VAE with 16x16 spatial and 8x temporal compression for efficiency.
✨ Video-DPO: Uses Direct Preference Optimization (DPO) on videos to improve visual quality.
🌐 Bilingual: Supports both Chinese and English prompts.
🏆 SOTA Performance: Achieves top results on their new Step-Video-T2V Eval benchmark.
There is a base model and a "Turbo" version, which leverages inference step distillation for increased speed.
You can try out text-to-video generation directly on their website.