
DeepHermes 3
Intuitive Responses and Deep Reasoning, in One Model.
78 followers
Intuitive Responses and Deep Reasoning, in One Model.
78 followers
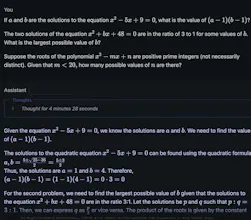
DeepHermes 3 from Nous Research is a Llama-3.1 8B based LLM with a toggleable reasoning mode for complex tasks. Combines fast responses with deep, chain-of-thought reasoning.




Flowtica Scribe
Chance AI: Curiosity Lens
This is an interesting evolution in LLMs! Building on Llama-3.1 8B with a toggleable reasoning mode is a clever approach to balancing quick responses with deeper analysis.
The innovation here seems to be the dual-mode capability:
Fast, intuitive responses for simple tasks
Chain-of-thought reasoning for complex problems
Being open source and built on a relatively compact 8B parameter model makes this particularly accessible for developers and researchers.
Really curious about:
What prompted the decision to make reasoning toggleable?
How does performance compare to larger models in each mode?
What types of tasks show the biggest benefits from the dual-mode approach?
Quick questions:
How do you determine when to switch modes?
What's the performance overhead of the reasoning mode?
Any plans for task-specific optimizations?
The launch engagement suggests there's significant interest in more flexible, efficient LLM architectures. You're essentially creating an adaptable model that can switch between quick and deep thinking modes!
Keep pushing the boundaries of LLM architecture - you're showing how models can be both efficient and thorough! 🧠⚡
Looking forward to seeing how the community builds on this. This feels like an important step in making LLMs more practically useful! 🚀
P.S. The open source nature could lead to interesting forks optimized for specific use cases.