Launching today

AISight
Understand how AI answer engines see your website
14 followers
Understand how AI answer engines see your website
14 followers
AISight analyzes AI crawler access, semantic structure, citation readiness and evidence quality, then generates an executive report with prioritized findings and copy-paste technical fixes for any public website.




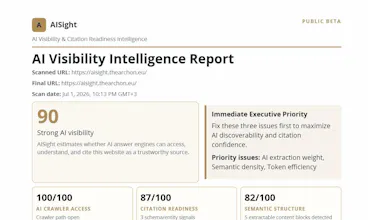

Does the executive report get generated on demand or do you run scheduled crawls, and how often does the underlying data refresh so the citation readiness scores actually reflect current site changes?
@hseyinrhrd Great question. The report is generated on demand from a fresh scan of the submitted public URL, so the scores reflect the site state observed at scan time. AISight does not currently run scheduled recurring crawls in the public beta. The next step is to make comparison over time more useful, so teams can see how visibility and citation readiness change after site updates. Thanks for raising this — it’s exactly the kind of question that helps shape the roadmap.
love the UI!
Also the fact that it gave my website a 100/100 score pretty much across the board made me happy NGL
It did surface some fixes around trust headers which was a quick fix. Thanks
@ankit_a hanks Ankit — this is exactly the kind of outcome I hoped AISight would produce: not just another score, but something specific enough to act on immediately. Great to hear the trust header finding led to a quick fix. Really appreciate you testing it and sharing the result.
The schema fix suggestions were actually paste-ready and made sense, which surprised me after seeing so many SEO tools that just yell about missing tags. Clean executive report too, no fluff.
@kezibannkbe Thanks, Keziban — that’s exactly what we wanted to achieve: not just flagging problems, but making the next step immediately actionable. Really appreciate you taking the time to look at the actual output.
How does AISight actually detect the AI crawlers in practice, does it rely on server log access or just passive DNS sniffing, and does that work for sites behind a CDN?