Launching today

Vouch
ai, agent
3 followers
ai, agent
3 followers
Vouch is durable, review-gated decision-memory for Gittensor (Bittensor SN74): a cited knowledge base that records why each scoring rule, allow-list, and emission-split decision was made — and what it superseded.
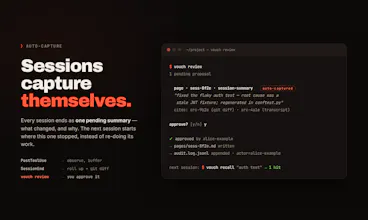


Hey Product Hunt 👋
Every persistent-memory tool for AI agents makes the same trade: the agent writes its own history, an LLM compresses it, and whatever it decided gets injected straight back into the next session. Nobody reviews it. If it hallucinated a "fact" on Monday, it's confidently citing itself by Wednesday.
vouch takes the opposite bet: memory should go through review, like code does.
One rule: every write passes a gate. The agent proposes a claim, you approve it, and only then does it become durable. Approved knowledge is plain YAML and markdown inside .vouch/ in your repo — so git is your audit log, PRs are your review UI, and the whole KB diffs cleanly.
What ships today:
🔒 Review gate — agents can't approve their own writes; try it, the server refuses
📎 Citations enforced — a claim without a source is a validation error, not a warning
🪝 Auto-capture — Claude Code hooks harvest each session into one pending summary, mechanically (no LLM), never auto-approved
🧠 Recall — the next session starts from what you approved, not from cold
🔌 MCP + JSONL + CLI — same surface for Claude Code, Cursor, Codex, and humans
📜 Append-only audit log — "which agent claimed what, citing what, when" for free
It's for teams where multiple agents share a repo, where sessions keep re-explaining the same context, or where you'd review an agent's claimed facts the way you review its code. (Gittensor SN74 miners: there's a template that seeds the scoring baseline — vouch init --template gittensor.)
Local-first, plain files, MIT, on PyPI:
`pipx install vouch-kb`
Still alpha and the surface is small on purpose. I'd love to hear where the review gate helps you — and where it gets in your way.
https://github.com/vouchdev/vouch