
OpenBI
AI-Native Business Intelligence Platform
36 followers
AI-Native Business Intelligence Platform
36 followers
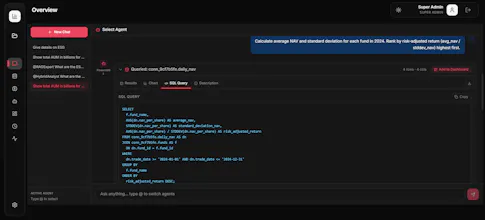
OpenBI is a self-hosted, open-source AI-native BI platform. Connect 90+ data sources (Postgres,MySQL & more), then ask questions in plain English - no SQL needed. What makes it different: • AI agents with text-to-SQL + RAG over your documents • Auto-generated AntV G2 charts from chat results • Drag-and-drop dashboards with real-time WebSocket updates • PDF & AI-powered PPTX export (Presenton) • Cron-scheduled reports via Email, Telegram & Webhook • Full Telegram bot for mobile access



























@mention @narenderkeswani Really interesting combination of AI-native analytics and self-hosting. The RAG layer over documents alongside text-to-SQL stands out, especially for teams whose knowledge is split between databases and internal docs. How do you handle accuracy and validation when an answer pulls from both structured data and unstructured documents in the same query?
@mention @nicole_hynek
That's a great question - validating hybrid queries is a complex topic. In OpenBI, we use a multi‑layer architecture that combines classic RAG testing principles with our own application‑specific checks.
Our approach uses a layered evaluation strategy for the different stages of a hybrid query: Data Ingestion, Retrieval, Generation, and Post‑Generation.
Layer 1: Data Ingestion Validation
Accuracy starts with the data itself.
* Structured Data (SQL): We use MindsDB's native text‑to‑SQL capabilities, which are validated on internal benchmarks.
* Unstructured Data (RAG): Documents are processed using a summarization module that produces a compact but information‑dense natural language representation, providing grounding context for all future operations.
Layer 2: Retrieval Validation
Hybrid queries require the system to know where to look.
* Structured Schema Retrieval (Text‑to‑SQL): We employ a schema‑guided RAG approach, combining structured knowledge graphs for relational reasoning with classic RAG for contextual grounding. This improves accuracy and explainability.
* Document Retrieval (Document RAG): We use standard `precision` and `recall` metrics to evaluate the quality of retrieved text chunks.
Layer 3: Generation Validation
We evaluate the final output for both syntactic and semantic correctness.
* Syntactic Validity: SQL generation is verified using `sqlparse`, acting as the first gate against malformed queries.
* Semantic Correctness and Intent Alignment: Both are evaluated using an LLM‑based assessment to check the logic and ensure the output truly addresses the user's original question.
Layer 4: Post‑Generation Validation & Observability
The final step is a final verification, supported by optional LLM call tracing via Langfuse or Normal DB storage. This provides observability across the entire system, allowing for performance audits and debugging.
Ultimately, it's this combination of techniques—from schema‑guided retrieval and modular evaluation to end‑to‑end LLM tracing -that allows OpenBI to deliver reliable answers from hybrid queries, even when the answer relies on disparate sources.
To have a good system we can add the LLM as Judge on top of each query - but ideally its on business requirement and use cases