
Launching today

Gemini API File Search
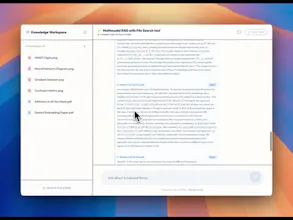
Index image, text file for multimodal RAG via the Gemini API
2 followers
Index image, text file for multimodal RAG via the Gemini API
2 followers
Gemini API File Search indexes image and text files, applies custom metadata filters, and returns page-level citations for developers building multimodal RAG pipelines.



The part of most RAG systems that quietly fails in production is not the retrieval, it is the verification.
What it is: an update to Gemini API File Search that adds multimodal retrieval, custom metadata filtering, and page-level citations to Google's managed RAG infrastructure tool for developers.
Teams building document-heavy AI applications run into a consistent problem: the model returns a confident answer but there is no clean way to show users where it came from.
Page citations in this update tie every response directly to a source page number, which converts the tool from a retrieval mechanism into something auditable.
Combined with multimodal support via Gemini Embedding 2, developers can now run a single query across an image and document corpus without building separate pipelines for each modality.
What makes it different: the metadata filtering layer is a practical addition that often goes unmentioned in RAG tooling. Attaching key-value labels to files at index time and using them to pre-filter at query time means the retrieval scope is already narrowed before the model does any work. At scale, this matters for both latency and accuracy.
Key features:
Image and text retrieval in a single query via Gemini Embedding 2
Custom metadata labels for structured filtering over unstructured file sets
Page-level citations returned with every retrieved result
Accessible via the Gemini API with no additional infrastructure required
Benefits:
Unified pipeline for mixed-modality corpora
Faster, more accurate retrieval through pre-query metadata scoping
Auditable outputs with source-level traceability
Reduced preprocessing burden for image-heavy datasets
Who it's for: developers and ML engineers building grounded, production-ready AI applications over large mixed-media file sets.
The broader pattern here is that retrieval quality alone is no longer the differentiator in RAG tooling. Verifiability and source attribution are becoming the baseline expectation, and this update reflects that shift clearly.