
Fous
Visual location intelligence for photos
11 followers
Visual location intelligence for photos
11 followers
Fous turns photos into location context. Upload an image and Fous estimates where it was taken by analyzing visible scene details, without relying on EXIF, GPS, or embedded metadata. The first preview focuses on San Francisco, with confidence-scored results, map review, and a workflow built for verification, research, investigations, trust and safety, and personal photo archives.


Hey Product Hunt 👋
I’m Vojtech, co-founder and CEO of Fous.
I’ve always found it strange how much location context can be hidden in plain sight. A street sign, a building edge, a storefront, the shape of a road, the way a city looks in the background. Humans can sometimes recognize those clues instantly, but doing it consistently from an image alone is much harder.
Fous is my attempt to make that workflow faster.
Upload a photo, and Fous estimates where it was taken by analyzing visible scene details. It does not rely on EXIF, GPS, or embedded metadata, so it can still work with screenshots, cropped images, video frames, and files where metadata is gone.
The first preview is focused on San Francisco. I chose one city on purpose: better coverage, clearer accuracy targets, and faster iteration before expanding.
What’s included today:
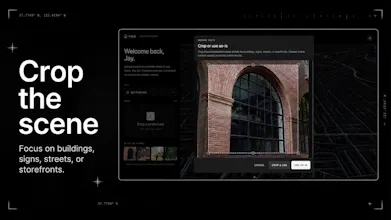
- Photo upload with crop support
- Location estimates from visual scene details
- Confidence-scored results
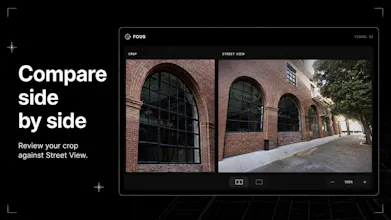
- Map-based review of possible matches
- No GPS or EXIF required
- A focused San Francisco preview
I think this can be useful anywhere location context matters: verification, research, investigations, trust and safety, journalism, and personal photo archives.
This is still an early preview, so I’m especially interested in the edge cases: images that fail, confusing results, scenes where confidence feels wrong, and workflows where this would be genuinely useful.
Try it here: https://fous.com
I’ll be around all day reading feedback and answering questions.
Jan from the Fous Team here.
What we’re launching today is a focused preview of visual geolocation. Unlike traditional tools, Fous ignores EXIF and GPS data - instead, it analyzes architectural cues, street morphology, and scene details to pinpoint a location.
The SF Preview Highlights:
Zero Metadata Required: Works on screenshots, crops, and video frames.
Hyper-Local Accuracy: Currently optimized for San Francisco to ensure high-fidelity results before we scale.
Verification Tools: Includes confidence scoring and an interactive map-review interface.
We’d love to hear from anyone in OSINT, journalism, research, or trust and safety. We’re especially looking for feedback on edge cases - where the AI misses the mark or where the workflow could be smoother.
Give it a spin: fous.com
Finally, a tool that could locate Hogwarts from a single owl-blurred screenshot. Asking for a friend. (Seriously though, the zero metadata angle is fascinating, the forensic journalism use case alone is compelling.)
@frogman12834 Thanks Marc, glad you like it. 🙂 The zero-metadata angle is exactly what we’re going for, especially for journalism / investigations.
@vojtechcekal Curious how Fous handles AI generated scenery... if the visual cues are plausible but fictional, does it confidently guess wrong or does the confidence score reflect the uncertainty?
@frogman12834 You make a great point. We don’t handle AI generated images yet. If the scene doesn’t line up with anything in SF, confidence will be low, but if an AI image looks very similar to a real SF spot, it can still score high. AI detection is coming soon, though.