
DeepSeek-V4
Towards Highly Efficient Million-Token Context Intelligence
1 follower
Towards Highly Efficient Million-Token Context Intelligence
1 follower
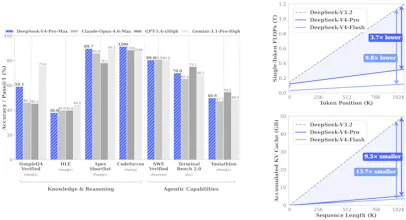
DeepSeek-V4 is a preview series of open Mixture-of-Experts LLMs: V4‑Pro (1.6T params, 49B active) and V4‑Flash (284B, 13B active), both with 1M-token context. New hybrid attention (CSA+HCA) cuts long-context compute and KV cache, plus mHC connections and the Muon optimizer for stability. Trained on 32T+ tokens and post-trained with expert specialization + consolidation.



HeyForm
DeepSeek‑V4 includes two open MoE models built for extreme long-context work:
DeepSeek‑V4‑Pro: 1.6T params (49B activated), 1M tokens
DeepSeek‑V4‑Flash: 284B params (13B activated), 1M tokens
What’s new under the hood:
Hybrid attention (CSA + HCA) for long-context efficiency — at 1M tokens, V4‑Pro uses ~27% of single-token inference FLOPs and 10% of KV cache vs DeepSeek‑V3.2
mHC (Manifold-Constrained Hyper-Connections) to improve signal propagation + stability
Muon optimizer for faster convergence and steadier training
Training notes: both models were pre-trained on 32T+ tokens, then post-trained via domain-expert SFT + RL (GRPO), followed by on-policy distillation to consolidate skills.