OpenJet
Code with a Local LLM in seconds.
4 followers
Code with a Local LLM in seconds.
4 followers
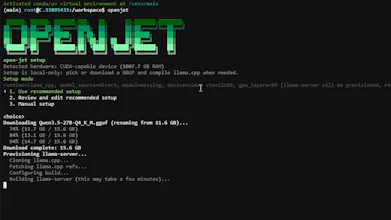
OpenJet is a terminal-based AI coding assistant that sets up your local LLM stack in seconds. Edit files, run shell commands, and resume coding sessions on your own hardware, safely and completely offline. It automatically detects your hardware to create a custom llama.cpp profile allowing you to set up your local LLM without prior experience.