
ReliAPI
Stop losing money on failed OpenAI and Anthropic API calls.
70 followers
Stop losing money on failed OpenAI and Anthropic API calls.
70 followers
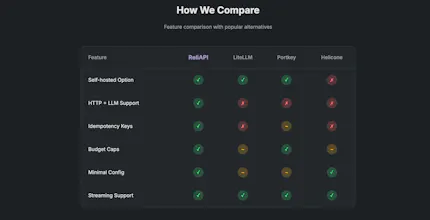
Unlike generic API proxies, ReliAPI is built specifically for LLM APIs (OpenAI, Anthropic, Mistral) and HTTP APIs. Key differentiators: • Smart caching reduces costs by 50-80% • Idempotency prevents duplicate charges • Budget caps reject expensive requests • Automatic retries with exponential backoff & circuit breaker • Real-time cost tracking for LLM calls • Works with OpenAI, Anthropic, Mistral, and HTTP APIs • Understands LLM challenges: token costs, streaming, rate limits Use from RapidAPI










ReliAPI
@kiku_reise ugh idempotency clicks killed me before, reliapi fixing that? finally no more double charges eating my wallet
ReliAPI
@masump Idempotency pain is exactly why I built it.
ReliAPI handles those accidental double-clicks for you, so you pay once no matter how many times the user smashes the button.
Glad it hits the spot!
RiteKit Company Logo API
Wore solutions like this are needed - limit our waste on AI tools.
Thank you!
ReliAPI
@osakasaul Couldn’t agree more. Wasted calls add up fast. Glad ReliAPI helps keep that burn rate down.
Great product! I'm curious about the smart caching mechanism. Is the time to live for cached responses configurable, or is there a fixed default duration?
ReliAPI
@new_user___3352025aaad15cafb976078 Thanks for asking.
Yes, the cache TTL is fully configurable per request. You can set it via the cache parameter (in seconds). For example:
"cache": 300 for 5 minutes
"cache": 3600 for 1 hour (default)
"cache": 86400 for 24 hours
If you don't specify it, we use the default from your configuration (typically 1 hour). This lets you balance content freshness with cost savings based on your use case.
Swytchcode
Nice work. Congrats on the launch!
ReliAPI
@chilarai Thanks a lot! Appreciate the support.
Great work. ReliAPI solves a real pain and does it cleanly. Congrats to you and the team.
ReliAPI
@nimaaksoy Thanks a lot! I really appreciate it. ReliAPI started as a tiny fix for the “double-charge pain,” and I’m glad it resonates with other developers.
No team yet — just me shipping fast. Your support means a lot.