
TransVoicely
Real-time transcription, translation & voice for live events
6 followers
Real-time transcription, translation & voice for live events
6 followers
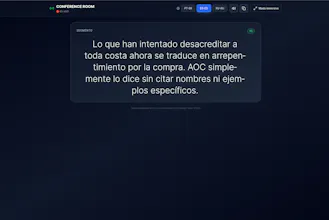
TransVoicely is an AI-powered platform that captures, transcribes, translates, synthesizes, and broadcasts audio in real time — enabling bidirectional conversations across different languages with low latency. Built for live events, churches, conferences, podcasts, and education, it offers 24/7 radio mode, multi-tenant control, smart automations, and instant streaming to web, mobile, and local devices. Simple, fast, and globally scalable.









Hi everyone! I’m the founder and lead developer of TransVoicely.
I built this platform because real-time multilingual communication is still too hard, too expensive, or too slow for most organizations. Churches, events, conferences, educators, and creators all face the same problem: they want to reach a global audience, but live translation tools are often limited or unreliable.
TransVoicely was created to fix that.
It captures audio, transcribes it, translates it into multiple languages, generates natural speech, and streams everything with ultra-low latency — usually under 1 second.
My goal is simple:
Make real-time global communication accessible to everyone.
If you have questions, feedback, or want to try it in your own live events, I’d love to talk.
Thanks so much for supporting this launch! 🙏
— Wallace B. de Laia
Founder & AI Software Engineer
Swytchcode
Congrats on the launch!
Does it help in clearing background noise?
@chilaraiYes, Transvoicely has a built-in noise reducer that does a good job, but if the noise is too loud and overlaps the speech, it will tend to ignore it in order to preserve transcription quality — so there is a limit. But you can test it and see how it performs in your case.