FissionBox, Early Beta Access
Build vision/YOLO models fast — without labelling data
6 followers
Build vision/YOLO models fast — without labelling data
6 followers
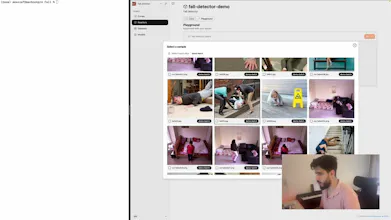
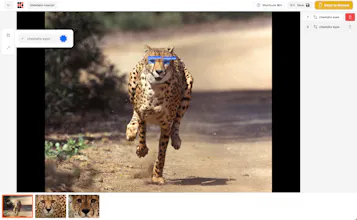
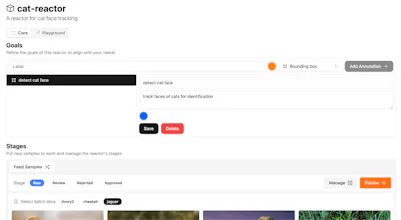
Simply upload footage, give the vision reactor a goal (e.g., "track cat faces"), click "fission", that's it! Now you download a labelled YOLO dataset and/or train a model. Built for devs, data scientists, and startups moving fast. Bye labelling!